
La Importancia del Aprendizaje Supervisado en la Inteligencia Artificial y el Aprendizaje Automático
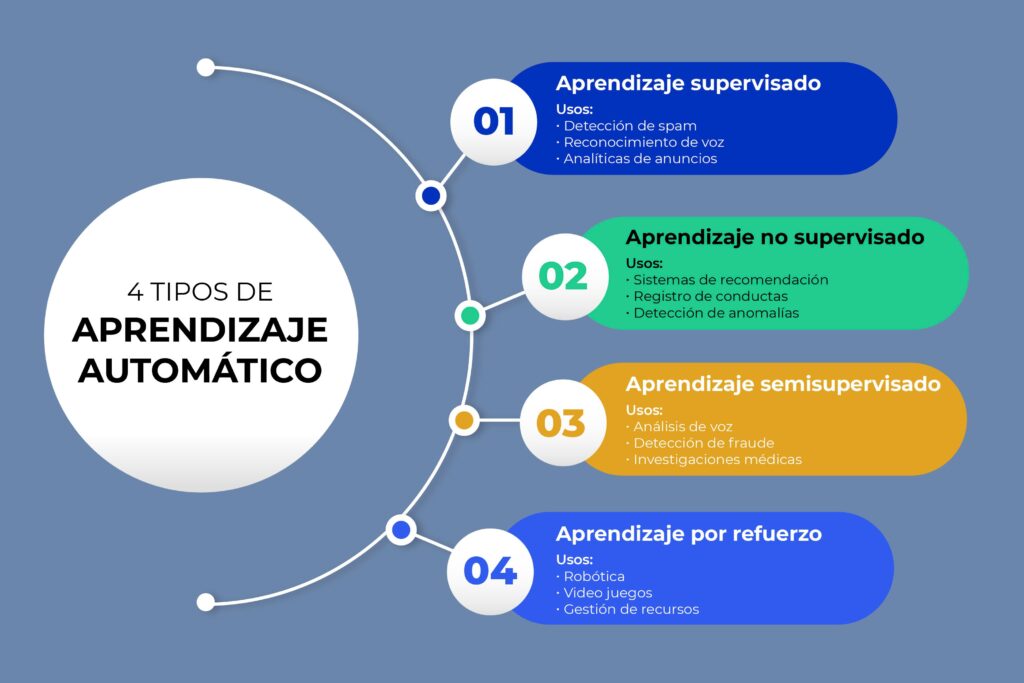
El aprendizaje supervisado es un componente fundamental en el desarrollo de sistemas de inteligencia artificial y aprendizaje automático. Este enfoque permite a las máquinas aprender de datos etiquetados, estableciendo relaciones entre entradas y salidas que son esenciales para realizar predicciones precisas en diversas aplicaciones.
En este contexto, La Importancia del Aprendizaje Supervisado en la Inteligencia Artificial y el Aprendizaje Automático radica en su capacidad para optimizar modelos y mejorar la eficiencia en tareas como clasificación y regresión. A medida que el volumen de datos crece, el aprendizaje supervisado se convierte en una herramienta clave para extraer conocimiento y tomar decisiones informadas en múltiples dominios.
Navega por nuestro contenido
- La relevancia del aprendizaje supervisado en la inteligencia artificial
- Cómo el aprendizaje supervisado potencia el aprendizaje automático
- Diferencias entre aprendizaje supervisado y no supervisado en IA
- Casos de éxito del aprendizaje supervisado en aplicaciones de IA
- Desafíos y oportunidades en el aprendizaje supervisado para la inteligencia artificial
- Tendencias futuras del aprendizaje supervisado en el aprendizaje automático
La relevancia del aprendizaje supervisado en la inteligencia artificial
La relevancia del aprendizaje supervisado en la inteligencia artificial se manifiesta en su capacidad para ofrecer soluciones efectivas en problemas del mundo real. Este enfoque permite que los modelos aprendan a partir de ejemplos previos, facilitando la identificación de patrones y tendencias en los datos. De este modo, las aplicaciones de aprendizaje supervisado abarcan desde el reconocimiento de voz hasta la detección de fraudes, impactando significativamente en la toma de decisiones.
Uno de los aspectos más destacados del aprendizaje supervisado es su versatilidad y adaptabilidad. A través de algoritmos como regresión lineal, máquinas de soporte vectorial y redes neuronales, se pueden abordar una amplia gama de tareas, tales como:
- Clasificación de imágenes
- Predicciones de ventas
- Análisis de sentimientos en redes sociales
Además, el aprendizaje supervisado se fundamenta en la calidad de los datos etiquetados. Un conjunto de datos bien diseñado y representativo es crucial para la eficacia del modelo, ya que influye directamente en su capacidad para generalizar a nuevos datos. Así, la selección y preparación adecuada de los datos es un paso esencial en el proceso de desarrollo de sistemas inteligentes.
Otro articulo de ayuda: Comprendiendo el GBM e Implementando Estrategias Efectivas para el Éxito
Comprendiendo el GBM e Implementando Estrategias Efectivas para el ÉxitoPor último, es importante resaltar el papel del aprendizaje supervisado en la mejora continua de los modelos. A medida que se recopilan más datos y se refinan los algoritmos, se logra una optimización constante que permite realizar predicciones cada vez más precisas. Esta característica es clave para aplicaciones críticas donde la precisión y la fiabilidad son fundamentales, como en el diagnóstico médico y la automatización industrial.
Cómo el aprendizaje supervisado potencia el aprendizaje automático
El aprendizaje supervisado potencia el aprendizaje automático al permitir que los modelos aprendan de ejemplos concretos. Este enfoque se basa en la utilización de un conjunto de datos etiquetados, donde cada entrada está asociada a una salida específica. De este modo, el modelo puede identificar patrones y relaciones que facilitan la predicción de resultados en situaciones similares, mejorando su rendimiento a lo largo del tiempo.
Una de las principales ventajas del aprendizaje supervisado es su capacidad para realizar predicciones precisas en diversas aplicaciones. A medida que se alimenta al modelo con más datos etiquetados, su habilidad para generalizar y responder adecuadamente a nuevos casos se incrementa significativamente. Esto se traduce en un impacto positivo en áreas como el reconocimiento de voz, la clasificación de imágenes y el análisis de datos financieros.
Además, el aprendizaje supervisado fomenta un ciclo de mejora continua. A través de la retroalimentación obtenida de las predicciones y su comparación con los resultados reales, los modelos pueden ser ajustados y optimizados. Este proceso no solo aumenta la precisión de las predicciones, sino que también permite a las organizaciones tomar decisiones más informadas y efectivas basadas en análisis de datos en tiempo real.
Finalmente, es crucial destacar la importancia de la calidad de los datos etiquetados en el aprendizaje supervisado. Un conjunto de datos robusto y bien estructurado es esencial para maximizar el rendimiento del modelo. Por ello, la inversión en la recopilación y etiquetado de datos adecuados resulta fundamental para garantizar que el aprendizaje automático sea efectivo y ayude a alcanzar los objetivos deseados en distintas industrias.
Diferencias entre aprendizaje supervisado y no supervisado en IA
El aprendizaje supervisado y el aprendizaje no supervisado son dos enfoques fundamentales en el campo de la inteligencia artificial. Mientras que el aprendizaje supervisado se basa en datos etiquetados, donde el modelo aprende a predecir salidas específicas a partir de entradas conocidas, el aprendizaje no supervisado trabaja con datos sin etiquetar, buscando patrones o agrupaciones internas sin una guía previa. Esta distinción es crucial para determinar el tipo de problema que se desea resolver.
Las características principales que diferencian estos dos enfoques incluyen:
- Datos: El aprendizaje supervisado requiere un conjunto de datos etiquetados, mientras que el no supervisado utiliza datos sin etiquetas.
- Objetivo: El objetivo del aprendizaje supervisado es la predicción, mientras que el aprendizaje no supervisado se centra en la exploración de datos.
- Aplicaciones: El aprendizaje supervisado se emplea en clasificación y regresión, mientras que el no supervisado es ideal para la agrupación y reducción de dimensionalidad.
Para entender mejor las diferencias, se puede observar la siguiente tabla:
| Aspecto | Aprendizaje Supervisado | Aprendizaje No Supervisado |
|---|---|---|
| Tipo de datos | Etiquetados | No etiquetados |
| Objetivo principal | Predicción | Exploración |
| Ejemplos de uso | Clasificación de correos electrónicos | Segmentación de clientes |
En resumen, la elección entre aprendizaje supervisado y no supervisado depende del contexto del problema y de la disponibilidad de datos. Mientras que el primero es más adecuado para tareas donde las relaciones son conocidas y se busca realizar predicciones, el segundo se enfoca en descubrir patrones ocultos en datos sin etiquetar, lo cual es vital para un análisis exploratorio más profundo.
Casos de éxito del aprendizaje supervisado en aplicaciones de IA
Existen numerosos casos de éxito en los que el aprendizaje supervisado ha transformado sectores enteros. En el ámbito de la salud, por ejemplo, algoritmos de aprendizaje supervisado han sido implementados para ayudar en el diagnóstico precoz de enfermedades como el cáncer. A través del análisis de imágenes médicas etiquetadas, los modelos pueden identificar anomalías con un alto grado de precisión, lo que facilita a los médicos tomar decisiones críticas sobre el tratamiento a seguir.
Otro notable caso de aplicación se encuentra en la industria de las finanzas, donde el aprendizaje supervisado se utiliza para detectar fraudes. Mediante el análisis de transacciones históricas etiquetadas como fraudulentas o legítimas, los modelos pueden aprender patrones y comportamientos inusuales, permitiendo así a las instituciones financieras actuar rápidamente y minimizar pérdidas. Este enfoque ha demostrado ser esencial para mejorar la seguridad en las operaciones bancarias.
En el sector de automoción, el aprendizaje supervisado ha impulsado el desarrollo de vehículos autónomos. Utilizando conjuntos de datos etiquetados que incluyen imágenes de carreteras, señales de tráfico y otros vehículos, los modelos pueden aprender a reconocer y reaccionar ante diferentes situaciones en tiempo real. Este avance no solo mejora la seguridad en la conducción, sino que también está allanando el camino hacia un futuro más sostenible en el transporte.
Finalmente, en el área de marketing digital, el aprendizaje supervisado permite realizar análisis de sentimientos en redes sociales. Al clasificar comentarios y opiniones etiquetados como positivos, negativos o neutrales, las empresas pueden comprender mejor la percepción de su marca. Esto les ayuda a ajustar estrategias de marketing y mejorar la relación con sus clientes, lo que se traduce en un aumento significativo en la lealtad y satisfacción del consumidor.
Desafíos y oportunidades en el aprendizaje supervisado para la inteligencia artificial
El aprendizaje supervisado enfrenta varios desafíos que pueden afectar su implementación y efectividad. Uno de los principales obstáculos es la calidad de los datos. Si los datos etiquetados contienen errores o son insuficientes, los modelos resultantes pueden producir predicciones inexactas. Además, la disponibilidad de datos puede ser limitada en ciertos dominios, lo que hace difícil entrenar modelos robustos y confiables. La variedad y complejidad de los datos también presentan dificultades, especialmente cuando se busca que el modelo generalice bien a situaciones no vistas.
A pesar de estos desafíos, el aprendizaje supervisado también ofrece numerosas oportunidades en el campo de la inteligencia artificial. Con el crecimiento exponencial de datos disponibles, las empresas pueden aprovechar técnicas avanzadas para crear modelos más precisos y eficientes. La automatización del etiquetado de datos mediante herramientas de aprendizaje activo y técnicas de aprendizaje profundo permite acelerar el proceso de preparación de datos, facilitando el desarrollo de modelos en tiempo récord. Asimismo, el uso de técnicas como la transferencia de aprendizaje abre nuevas posibilidades para aplicar modelos preentrenados en tareas específicas con menos datos.
Otro aspecto prometedor es la capacidad de los modelos supervisados para adaptarse a cambios en el entorno. A medida que se recopilan nuevos datos, los modelos pueden ser ajustados y recalibrados para reflejar tendencias actuales, asegurando así su relevancia y eficacia. Esto es especialmente importante en áreas como el análisis de mercado y la detección de fraudes, donde los patrones pueden cambiar rápidamente. Además, la integración de aprendizaje supervisado con otras técnicas de inteligencia artificial, como el aprendizaje no supervisado, puede generar modelos más robustos y versátiles.
Por último, es esencial mencionar que la colaboración interdisciplinaria puede amplificar las oportunidades del aprendizaje supervisado. Al trabajar junto con expertos en el dominio específico, los científicos de datos pueden obtener una comprensión más profunda de los problemas a resolver, lo que les permite diseñar modelos más alineados con las necesidades reales. Esta sinergia entre áreas como la estadística, la informática y el conocimiento del negocio es clave para maximizar el impacto del aprendizaje supervisado en la inteligencia artificial.
Tendencias futuras del aprendizaje supervisado en el aprendizaje automático
Las tendencias futuras del aprendizaje supervisado en el aprendizaje automático apuntan hacia una mayor integración de técnicas de inteligencia artificial explicativa. Esta tendencia busca no solo mejorar la precisión de los modelos, sino también entender cómo y por qué toman decisiones específicas. La capacidad de proporcionar explicaciones claras sobre las predicciones de un modelo se convierte en un requisito esencial en sectores críticos como la salud y las finanzas, donde la transparencia es crucial para la confianza de los usuarios.
Otra tendencia significativa es el avance en la automatización del etiquetado de datos. Con el uso de algoritmos de aprendizaje activo y técnicas de transferencia de aprendizaje, las organizaciones podrán reducir el tiempo y el esfuerzo necesarios para etiquetar grandes volúmenes de datos. Esto facilitará la creación de conjuntos de datos más ricos y diversos, lo que a su vez mejorará la calidad de los modelos desarrollados.
Además, se espera un aumento en el uso de modelos híbridos que combinan aprendizaje supervisado con enfoques no supervisados o de refuerzo. Esta combinación permitirá a los sistemas aprender de manera más eficiente, adaptándose a nuevos patrones y cambios en los datos. Los modelos híbridos pueden ser particularmente útiles en aplicaciones dinámicas, como la predicción de tendencias de mercado o la detección de fraudes en tiempo real.
Por último, la implementación de enfoques de aprendizaje federado está ganando terreno. Esta técnica permite que múltiples dispositivos colaboren en el entrenamiento de modelos sin compartir datos sensibles, lo que es especialmente relevante en el contexto de la privacidad y la seguridad de los datos. A medida que la preocupación por la privacidad de los datos crece, el aprendizaje federado podría ofrecer una solución efectiva para utilizar el aprendizaje supervisado en entornos más seguros y responsables.
¿Usar mucho el celular hace daño? Descubre la verdad

Explorando el Fenómeno de Villanosam Me Va Quema El Celular

Razones por las que tu celular se calienta y soluciones

Qué sucede si no cargas el celular nuevo 12 horas
Descubre qué significa mm en el contexto de tu celular

Descubre el mundo de los tonos de llamada Rin Rin Ton
Deja una respuesta
Contenido relacionado