Comprendiendo el concepto de unknown encoding en la programación
La programación moderna enfrenta numerosos desafíos relacionados con el manejo de texto y datos. Uno de los conceptos más intrigantes y complejos es el de la codificación desconocida, que puede dar lugar a errores y problemas de interpretación en los sistemas. Comprendiendo el concepto de unknown encoding en la programación, los desarrolladores pueden abordar de manera más efectiva las dificultades asociadas con la manipulación de datos en diferentes contextos y entornos.
El unknown encoding se refiere a situaciones en las que la codificación de un conjunto de caracteres no se encuentra especificada o no es reconocida por el sistema. Esto puede suceder al procesar archivos o datos provenientes de diversas fuentes, lo que puede resultar en una presentación incorrecta de la información. Al profundizar en este tema, se busca ofrecer herramientas y conocimientos que faciliten la correcta gestión de la codificación en los proyectos de programación.
Navega por nuestro contenido
- ¿Qué es el unknown encoding y cómo afecta a la programación?
- Importancia del manejo de unknown encoding en el desarrollo de software
- Errores comunes relacionados con unknown encoding en aplicaciones
- Cómo detectar y corregir unknown encoding en tus proyectos
- Prácticas recomendadas para evitar problemas de unknown encoding
- Impacto del unknown encoding en la interoperabilidad de sistemas
¿Qué es el unknown encoding y cómo afecta a la programación?
El unknown encoding representa un desafío significativo en la programación, ya que puede llevar a errores de interpretación y a la pérdida de información crítica. Cuando un sistema no puede determinar la codificación de un archivo, los caracteres pueden aparecer corruptos o ininteligibles, lo que afecta directamente a la usabilidad y la funcionalidad de una aplicación. Por lo tanto, comprender cómo se manifiesta este problema es esencial para cualquier desarrollador.
Las causas del unknown encoding pueden ser variadas, pero a menudo incluyen:
- Transferencias de datos entre diferentes plataformas o sistemas.
- Archivos generados por aplicaciones sin un estándar de codificación claro.
- Datos provenientes de fuentes externas sin metadatos adecuados.
En consecuencia, los desarrolladores deben implementar estrategias que les permitan detectar y manejar estas situaciones, asegurando que los datos se interpreten correctamente y evitando así posibles fallos en la aplicación.
Otro articulo de ayuda: La importancia de los protocolos ARP en las redes de datos y su funcionamiento
La importancia de los protocolos ARP en las redes de datos y su funcionamientoUna de las formas de abordar el unknown encoding es estableciendo un proceso de validación que permita identificar la codificación de los datos. Esto puede incluir:
- Uso de bibliotecas que detectan automáticamente la codificación.
- Conversión de archivos a un formato estándar conocido, como UTF-8.
- Incorporar documentación sobre la codificación utilizada en los sistemas que interactúan.
Al adoptar estas prácticas, los programadores pueden minimizar los riesgos asociados con el manejo de datos y mejorar la interoperabilidad entre diferentes sistemas.
Importancia del manejo de unknown encoding en el desarrollo de software
El manejo adecuado del unknown encoding es crucial en el desarrollo de software, ya que permite a los programadores evitar errores de interpretación que pueden afectar la calidad y la fiabilidad de las aplicaciones. Cuando se gestionan datos con codificaciones no especificadas, el riesgo de que la información se presente de manera incorrecta aumenta significativamente, lo que puede tener consecuencias graves en la experiencia del usuario y en la funcionalidad general del sistema.
Además, un buen manejo del unknown encoding contribuye a la interoperabilidad entre diferentes plataformas y sistemas. Al garantizar que los caracteres y datos se interpreten correctamente, se facilita la comunicación entre aplicaciones que pueden tener distintos estándares de codificación. Esto es especialmente importante en entornos donde se intercambian grandes volúmenes de información, como en APIs o sistemas distribuidos.
Para abordar efectivamente el unknown encoding, es recomendable que los desarrolladores implementen prácticas de programación que incluyan:
- Establecimiento de estándares de codificación a nivel de proyecto.
- Uso de herramientas de validación que identifiquen automáticamente la codificación de los datos.
- Formación continua en buenas prácticas de manejo de datos y codificaciones.
Al incorporar estas estrategias, se pueden minimizar los errores y optimizar la gestión de datos, lo que resulta en aplicaciones más robustas y seguras.
Finalmente, es importante destacar que el desconocimiento de la codificación puede generar problemas de seguridad. Los datos mal interpretados pueden ser vulnerables a ataques como la inyección de código o la manipulación de información. Por ende, comprender y manejar adecuadamente el unknown encoding no solo mejora la calidad del software, sino que también fortalece su seguridad.
Errores comunes relacionados con unknown encoding en aplicaciones
Uno de los errores más comunes relacionados con el unknown encoding en aplicaciones es la falta de especificación de la codificación en los archivos de entrada. Esto puede llevar a que el sistema interprete incorrectamente los caracteres, resultando en un comportamiento inesperado. En ocasiones, los desarrolladores asumen que un archivo tiene una codificación específica, lo que puede llevar a errores de representación de datos. Las consecuencias suelen incluir:
- Fallos en la visualización de texto.
- Errores en el procesamiento de datos.
- Inconsistencias en la base de datos.
Otro error común es omitir la conversión a un formato estándar, como UTF-8, antes de procesar datos. Sin una conversión adecuada, los caracteres especiales pueden corromperse y provocar errores difíciles de rastrear. Este tipo de problemas es especialmente frecuente al trabajar con aplicaciones que manejan múltiples idiomas y conjuntos de caracteres. Algunas soluciones incluyen:
- Implementar validaciones previas a la carga de datos.
- Utilizar bibliotecas que automaticen la conversión de codificación.
- Proporcionar documentación clara sobre el manejo de codificaciones en el proyecto.
Los problemas de unknown encoding también pueden surgir cuando se intercambian datos entre sistemas que utilizan diferentes estándares de codificación, lo que puede resultar en la pérdida de información. Este tipo de escenarios es común en aplicaciones que integran APIs de terceros. Para mitigar estos riesgos, es recomendable seguir ciertas prácticas, como:
- Establecer protocolos claros de intercambio de datos.
- Realizar pruebas exhaustivas de integración.
- Contar con un sistema de logging para rastrear errores de codificación.
Finalmente, los errores relacionados con el unknown encoding pueden tener implicaciones en la seguridad de la aplicación. La corrupción de datos puede abrir puertas a vulnerabilidades, como inyecciones de código. Por lo tanto, es crucial que los desarrolladores sean proactivos en el manejo de la codificación para no solo mejorar la funcionalidad de la aplicación, sino también su seguridad general.
Cómo detectar y corregir unknown encoding en tus proyectos
Detectar y corregir el unknown encoding en tus proyectos puede ser un proceso esencial para asegurar la integridad de los datos. Para comenzar, es recomendable utilizar herramientas de análisis que puedan identificar la codificación de archivos automáticamente. Este paso inicial permite a los desarrolladores tener una mejor comprensión de cómo se están manejando los datos antes de realizar cualquier manipulación.
Una estrategia eficaz para lidiar con el unknown encoding es la normalización de archivos. Esto implica convertir todos los documentos a un formato estándar, como UTF-8, antes de procesarlos. Al hacerlo, se minimizan los riesgos de presentación incorrecta de los caracteres y se facilita la interoperabilidad entre diferentes sistemas, lo que es fundamental en entornos de desarrollo complejos.
Además, es vital establecer un proceso de documentación sobre la codificación utilizada en cada proyecto. La falta de claridad sobre qué codificación se debe emplear puede conducir a malentendidos y errores en el manejo de datos. Mantener un registro claro de las codificaciones permite a cada miembro del equipo trabajar con la misma base y reduce la posibilidad de errores.
Por último, implementar pruebas automatizadas que verifiquen la correcta representación de los caracteres puede ser un buen enfoque preventivo. Estas pruebas deben ejecutarse regularmente para identificar cualquier problema de unknown encoding antes de que se conviertan en un inconveniente mayor. Al integrar estos pasos en el flujo de trabajo, los desarrolladores pueden asegurar una mejor calidad en el manejo de datos y, por ende, en el funcionamiento de sus aplicaciones.
Prácticas recomendadas para evitar problemas de unknown encoding
Para evitar problemas de unknown encoding, es fundamental establecer un estándar de codificación desde el inicio de un proyecto. Utilizar una codificación uniforme, como UTF-8, para todos los archivos de texto garantiza que los caracteres sean interpretados de manera consistente. Esto no solo facilita el manejo de datos, sino que también reduce la posibilidad de errores al integrar múltiples fuentes de información. Al adoptar esta práctica, se minimizan los riesgos de interpretar incorrectamente los datos.
Otra recomendación esencial es realizar pruebas de validación de codificación en todas las etapas del desarrollo. Implementar herramientas que detecten y alerten sobre posibles problemas de codificación puede ayudar a identificar errores antes de que se conviertan en un problema. Estas herramientas deben analizar los archivos de entrada y salida, asegurando que se mantenga la integridad de la información. Además, se recomienda documentar cualquier peculiaridad en la codificación utilizada para facilitar la colaboración entre los miembros del equipo.
Asimismo, es clave fomentar una cultura de formación continua en el manejo de codificaciones. Los desarrolladores deben estar al tanto de las mejores prácticas para el tratamiento de datos, incluyendo la importancia de la normalización de formatos. Esto puede incluir la conversión periódica de archivos a una codificación estándar y la capacitación sobre cómo manejar diferentes conjuntos de caracteres. Al invertir en la educación del equipo, se puede reducir considerablemente el riesgo de errores relacionados con el unknown encoding.
Finalmente, al trabajar con APIs o sistemas externos, es recomendable establecer protocolos claros de intercambio de datos. Asegurarse de que ambas partes conozcan y utilicen el mismo estándar de codificación es esencial para evitar problemas de incompatibilidad. Considerar incluir en la documentación técnica la codificación utilizada y realizar revisiones regulares del sistema ayudará a mantener un entorno de trabajo más sano y libre de sorpresas indeseadas relacionadas con la codificación.
Impacto del unknown encoding en la interoperabilidad de sistemas
El unknown encoding puede tener un impacto significativo en la interoperabilidad de sistemas, especialmente en entornos donde se requiere el intercambio de datos entre diferentes plataformas. Cuando un sistema no puede determinar la codificación de los datos recibidos, se corre el riesgo de que la información se interprete incorrectamente, lo que puede generar fallos en la comunicación entre aplicaciones. Esto es particularmente problemático cuando se manejan grandes volúmenes de información, ya que la pérdida de datos importantes puede afectar a toda la operación del sistema.
La falta de un estándar de codificación puede llevar a inconsistencias en la presentación de la información. Por ejemplo, al integrar aplicaciones que utilizan distintas codificaciones, pueden ocurrir problemas como:
- Errores en la visualización de datos.
- Inconsistencias en el almacenamiento de información.
- Fallas en la ejecución de funciones críticas, como la búsqueda o el procesamiento de datos.
Además, el unknown encoding puede afectar negativamente la experiencia del usuario. Si los caracteres no se presentan correctamente, esto puede resultar en interfaces difíciles de usar, confusas o, en el peor de los casos, en datos perdidos. Para mitigar estos problemas, es fundamental que los desarrolladores implementen prácticas que aseguren una codificación uniforme y estandarizada en todos los componentes del sistema.
La implementación de protocolos claros y la documentación precisa sobre la codificación utilizada en cada sistema son pasos cruciales para mejorar la interoperabilidad. Al establecer un marco común en el que todos los sistemas operen con el mismo estándar de codificación, se facilita la comunicación y se reducen los errores asociados con el unknown encoding. Esto no solo garantiza la integridad de los datos, sino que también mejora la colaboración entre equipos de desarrollo.
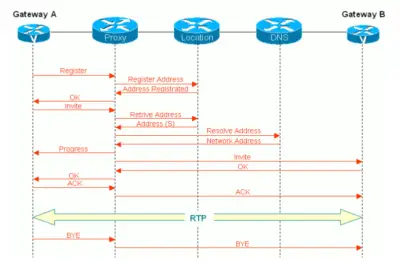
Los principales protocolos de VoIP de acuerdo al modelo OSI
El proceso de encapsulamiento y desencapsulamiento en el modelo OSI explicado de manera clara

La historia del modelo OSI y su importancia en las redes de comunicación
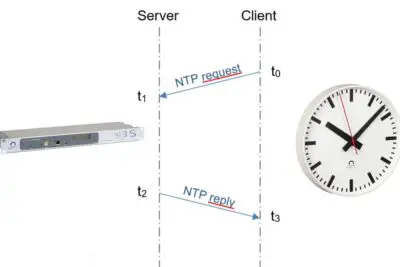
Comprendiendo el servicio NTP y su importancia en la sincronización del tiempo en redes informáticas
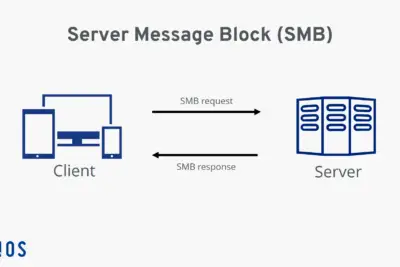
La importancia del Server Message Block en la comunicación de redes
Comprensión profunda de las direcciones IP en redes y su funcionalidad
Deja una respuesta
Contenido relacionado