Guía completa sobre el sistema de archivos distribuido HDFS para el almacenamiento de datos
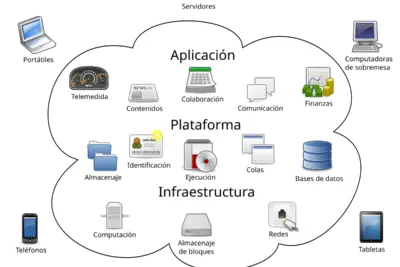
En la era del Big Data, el almacenamiento eficiente y escalable de grandes volúmenes de datos se ha convertido en una prioridad para las organizaciones. El sistema de archivos distribuido HDFS se presenta como una solución robusta que permite almacenar y gestionar datos de manera efectiva, garantizando alta disponibilidad y rendimiento.
Esta Guía completa sobre el sistema de archivos distribuido HDFS para el almacenamiento de datos tiene como objetivo ofrecer una visión detallada de sus características, arquitectura y funcionamiento. A lo largo de este artículo, exploraremos cómo HDFS se adapta a las necesidades cambiantes de las empresas en un entorno digital en constante evolución.
Navega por nuestro contenido
- Introducción al sistema de archivos distribuido HDFS y su importancia en el almacenamiento de datos
- Arquitectura de HDFS: cómo funciona el sistema de archivos distribuido
- Ventajas de utilizar HDFS para el almacenamiento de grandes volúmenes de datos
- Configuración y despliegue de un clúster HDFS para almacenamiento eficiente
- Mantenimiento y gestión de datos en HDFS: mejores prácticas
- Comparativa entre HDFS y otros sistemas de archivos distribuidos en el mercado
Introducción al sistema de archivos distribuido HDFS y su importancia en el almacenamiento de datos
El sistema de archivos distribuido HDFS, acrónimo de Hadoop Distributed File System, se ha convertido en una pieza clave en la infraestructura del Big Data. Su diseño está optimizado para almacenar grandes cantidades de datos en múltiples nodos a través de una red, lo que proporciona una alta disponibilidad y resistencia ante fallos. Esta capacidad de distribución permite a las organizaciones manejar datos de manera más eficiente y a gran escala.
Una de las razones de la creciente importancia de HDFS en el almacenamiento de datos es su escalabilidad. A medida que las necesidades de almacenamiento crecen, HDFS permite añadir más nodos al sistema sin complicaciones. Entre sus características más destacadas se incluyen:
- Almacenamiento de datos masivos: Capaz de gestionar petabytes de información.
- Acceso rápido a los datos: Optimizado para la lectura y escritura de grandes bloques de datos simultáneamente.
- Resiliencia a fallos: Replicación automática de datos en diferentes nodos para garantizar la integridad.
Además, HDFS es fundamental para la ejecución de aplicaciones analíticas en tiempo real y para el procesamiento de datos en entornos donde la velocidad es crucial. Gracias a su arquitectura, permite la integración con otras herramientas del ecosistema Hadoop, facilitando flujos de trabajo complejos y la interoperabilidad entre diferentes sistemas. Esto lo hace indispensable para empresas que buscan obtener insights valiosos de sus datos.
Otro articulo de ayuda: Comprendiendo los Modelos de Datos en el Desarrollo de Sistemas de Información
Comprendiendo los Modelos de Datos en el Desarrollo de Sistemas de InformaciónArquitectura de HDFS: cómo funciona el sistema de archivos distribuido
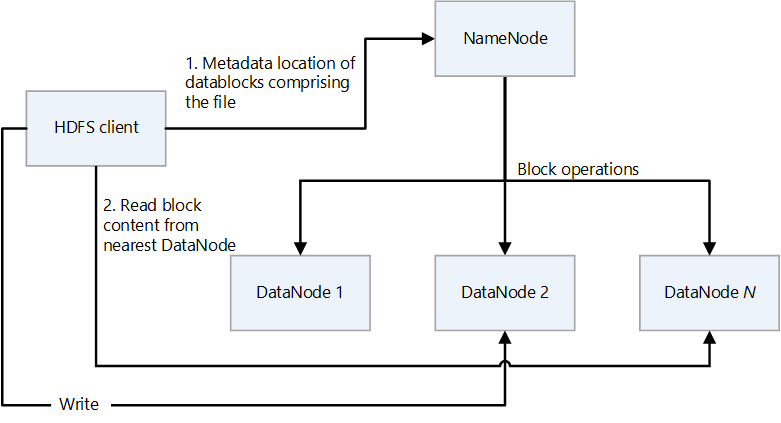
La arquitectura de HDFS se basa en un modelo maestro-esclavo, donde el NameNode actúa como el nodo maestro que gestiona la estructura del sistema de archivos y la ubicación de los bloques de datos. Por su parte, los DataNodes son los nodos esclavos responsables del almacenamiento efectivo de los datos. Esta separación de responsabilidades permite una gestión eficiente de los recursos y facilita la recuperación de datos en caso de fallos.
Un aspecto clave de la arquitectura de HDFS es la replicación de datos. Cada bloque de datos se replica en múltiples DataNodes, lo que garantiza la disponibilidad y durabilidad de la información. Por defecto, HDFS realiza tres copias de cada bloque, aunque este número puede ajustarse según las necesidades específicas de la organización. La replicación no solo proporciona tolerancia a fallos, sino que también mejora el rendimiento al permitir que los datos sean accesibles desde diferentes nodos.
La comunicación entre el NameNode y los DataNodes se realiza a través de un protocolo específico que asegura la sincronización y el mantenimiento de la coherencia en el sistema. Los DataNodes envían periódicamente informes de estado al NameNode, lo que permite a este último tener una visión clara del estado de la red y realizar ajustes cuando sea necesario. Esta dinámica de comunicación es fundamental para el funcionamiento fluido de HDFS.
Finalmente, la arquitectura de HDFS está diseñada para ser altamente escalable. A medida que las necesidades de almacenamiento aumentan, se pueden añadir nuevos DataNodes al cluster sin interrumpir el servicio. Esta escalabilidad horizontal permite a las organizaciones adaptar su infraestructura a las crecientes demandas de datos, asegurando que HDFS continúe proporcionando un rendimiento óptimo a largo plazo.
Ventajas de utilizar HDFS para el almacenamiento de grandes volúmenes de datos
Una de las principales ventajas de utilizar HDFS para el almacenamiento de grandes volúmenes de datos es su alta disponibilidad. Gracias a la replicación de datos en múltiples nodos, HDFS asegura que la información esté siempre accesible, incluso en caso de fallos de hardware. Este enfoque no solo protege contra la pérdida de datos, sino que también mejora la fiabilidad del sistema, lo cual es crucial para las aplicaciones empresariales que dependen de datos críticos.
Otro aspecto destacado de HDFS es su capacidad de escalabilidad. A medida que crece el volumen de datos, HDFS permite la incorporación de nuevos nodos de manera sencilla y sin interrupciones. Esta escalabilidad horizontal se traduce en una mayor flexibilidad para las empresas, que pueden adaptarse rápidamente a las fluctuaciones en sus necesidades de almacenamiento. Las características clave de esta ventaja incluyen:
- Expansión sencilla: Agregar nuevos nodos sin afectar el rendimiento.
- Costos reducidos: Utilización de hardware estándar para la creación de clusters.
- Adaptación a necesidades variables: Posibilidad de ajustar la capacidad de almacenamiento de forma dinámica.
Además, HDFS está diseñado para optimizar el procesamiento de datos masivos, lo que permite ejecutar análisis complejos de manera eficiente. Su arquitectura permite el acceso concurrente a los datos, facilitando que múltiples procesos de lectura y escritura se realicen simultáneamente. Esto es particularmente beneficioso en entornos donde se requiere un análisis en tiempo real, lo que ofrece a las organizaciones una ventaja competitiva significativa.
Finalmente, HDFS proporciona un modelo de gestión de datos que es tanto robusto como fácil de usar. La interfaz de HDFS permite a los desarrolladores y administradores interactuar con el sistema de archivos de forma intuitiva, lo que acelera la implementación y el mantenimiento de soluciones de Big Data. Esta combinación de facilidad de uso y potencia técnica hace de HDFS una opción preferida para el almacenamiento de grandes volúmenes de datos en diversas industrias.
Configuración y despliegue de un clúster HDFS para almacenamiento eficiente
La configuración y despliegue de un clúster HDFS para un almacenamiento eficiente es crucial para maximizar el rendimiento del sistema. Para iniciar, es fundamental definir el número de nodos que formarán parte del clúster, ya que esto afectará directamente la capacidad de almacenamiento y la resiliencia del mismo. Un clúster típicamente incluye un NameNode y varios DataNodes, donde el primero se encarga de gestionar el sistema de archivos y los segundos almacenan los datos distribuidos.
Una vez definidos los nodos, se debe proceder a la instalación de Hadoop en cada uno de ellos. Este proceso incluye la configuración de archivos clave, como el hdfs-site.xml y core-site.xml, donde se especifican las propiedades del sistema, tales como la ubicación del NameNode y el tamaño de los bloques de datos. Además, es recomendable implementar medidas de seguridad, como el uso de Kerberos para la autenticación, que protegen los datos almacenados en el clúster.
Posteriormente, es importante realizar pruebas de rendimiento para asegurar que el clúster esté correctamente optimizado. Esto puede incluir la evaluación de la velocidad de lectura y escritura de datos, así como la monitorización del uso de recursos. Herramientas como Apache Ambari pueden ser útiles para la supervisión continua del clúster y para identificar posibles cuellos de botella en el rendimiento. Además, es recomendable establecer un plan de replicación de datos que se ajuste a las necesidades de la organización, garantizando así la integridad y disponibilidad de la información.
Finalmente, un clúster HDFS bien configurado no solo ayuda a almacenar datos de manera eficiente, sino que también facilita el procesamiento de grandes volúmenes de información en tiempo real. Implementar prácticas de mantenimiento regulares y realizar auditorías de seguridad asegurará que el clúster siga funcionando de manera óptima a medida que la organización crezca y sus necesidades cambien.
Mantenimiento y gestión de datos en HDFS: mejores prácticas
El mantenimiento y gestión de datos en HDFS es crucial para asegurar un rendimiento óptimo y la disponibilidad de la información. Una de las mejores prácticas es realizar auditorías periódicas del sistema de archivos para identificar y resolver problemas potenciales antes de que afecten el rendimiento. Esto incluye la verificación de la salud de los DataNodes y la revisión de los registros del sistema para detectar cualquier anomalía que pueda surgir. Mantener un monitoreo constante permite anticiparse a fallos y garantizar la integridad de los datos almacenados.
Otra recomendación importante es implementar un plan de replicación de datos que se ajuste a las necesidades de la organización. La configuración predeterminada de tres copias de cada bloque puede ser adecuada para muchas aplicaciones, pero algunas situaciones pueden requerir un mayor o menor nivel de replicación. Ajustar este parámetro según la criticidad de los datos y el costo asociado puede mejorar la eficiencia del almacenamiento y reducir el uso innecesario de recursos.
Además, es fundamental establecer políticas claras de gestión de datos para optimizar el uso del espacio en HDFS. Esto incluye la eliminación de datos obsoletos, la compresión de archivos y la organización adecuada de los datos en directorios. Utilizar herramientas de análisis y limpieza de datos puede ayudar a mantener el sistema ordenado, mejorando así la eficiencia en las operaciones de lectura y escritura.
Finalmente, la capacitación del personal en el uso y mantenimiento de HDFS no debe ser subestimada. Proporcionar formación regular sobre las mejores prácticas y las nuevas funcionalidades del sistema puede maximizar el rendimiento y la seguridad del clúster. Implementar un programa de formación continua asegura que los administradores y desarrolladores estén actualizados sobre las últimas técnicas y herramientas disponibles para la gestión de datos en HDFS.
Comparativa entre HDFS y otros sistemas de archivos distribuidos en el mercado
Al comparar HDFS con otros sistemas de archivos distribuidos, como Ceph y GlusterFS, es esencial considerar aspectos como la escalabilidad, la administración y el rendimiento. HDFS se distingue por su capacidad de manejar grandes volúmenes de datos de manera eficiente, mientras que Ceph ofrece una mayor flexibilidad en la gestión de almacenamiento en bloque y archivos, siendo ideal para aplicaciones que requieren un acceso aleatorio más rápido. Por su parte, GlusterFS se destaca en la facilidad de configuración y en la replicación de datos en tiempo real, lo cual puede ser ventajoso para ciertas arquitecturas de nube.
Una tabla comparativa puede ayudar a visualizar las diferencias clave entre estos sistemas de archivos distribuidos:
| Sistema de Archivos | Escalabilidad | Tipo de Almacenamiento | Facilidad de Configuración |
|---|---|---|---|
| HDFS | Alta | Datos masivos | Moderada |
| Ceph | Muy alta | Bloque y objeto | Alta |
| GlusterFS | Alta | Archivo y objeto | Alta |
Otro aspecto a considerar es la replicación de datos. HDFS permite la replicación por defecto de tres copias de cada bloque de datos, lo que garantiza una alta disponibilidad y durabilidad. En contraste, Ceph utiliza un enfoque más dinámico con su algoritmo CRUSH, permitiendo una distribución más equilibrada de los datos, mientras que GlusterFS ofrece una replicación sencilla que se puede establecer según las necesidades específicas del usuario. Esta variabilidad en la gestión de datos es crucial a la hora de elegir el sistema adecuado para diferentes escenarios de almacenamiento.
Finalmente, la elección entre HDFS y otros sistemas de archivos distribuidos dependerá en gran medida de las necesidades específicas de la organización. Factores como el tipo de aplicación, la naturaleza de los datos y el presupuesto existente jugarán un papel crucial en la decisión. Con una comprensión clara de las fortalezas y debilidades de cada sistema, las empresas pueden implementar la solución de almacenamiento más adecuada para su entorno de Big Data.
Programación Web: Cómputo en la Nube y Servicios

Diferencias clave entre computación e informática hoy
Cómo el Cómputo en la Nube Impulsa el Big Data

Cuántos puertos USB tiene una computadora típica

¿Por qué la computadora maneja 8 bits de datos?
Definición completa y funciones de una computadora
Deja una respuesta
Contenido relacionado