
Cómo realizar operaciones relacionales en bases de datos de manera efectiva
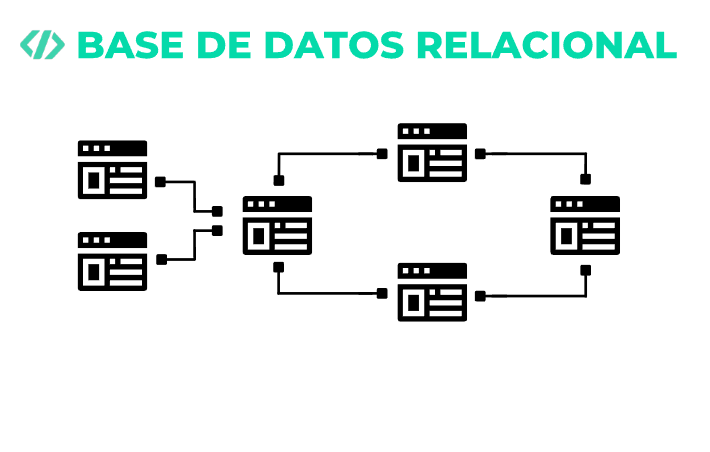
Las bases de datos relacionales son fundamentales en el manejo de información estructurada, permitiendo interacciones eficientes entre datos a través de operaciones como selecciones, uniones y proyecciones. Sin embargo, realizar estas operaciones de manera correcta y optimizada es crucial para garantizar la integridad y el rendimiento del sistema.
En este contexto, aprender cómo realizar operaciones relacionales en bases de datos de manera efectiva se convierte en una habilidad indispensable para desarrolladores y analistas de datos. A través de un enfoque metódico y el uso de herramientas adecuadas, se pueden maximizar los beneficios de las bases de datos, optimizando consultas y mejorando la experiencia del usuario final.
Navega por nuestro contenido
- Cómo optimizar tus consultas SQL para operaciones relacionales eficientes
- Los diferentes tipos de operaciones relacionales en bases de datos: una guía completa
- Mejores prácticas para realizar uniones (JOIN) en bases de datos
- Errores comunes en operaciones relacionales y cómo evitarlos
- La importancia de índices en operaciones relacionales en bases de datos
- Cómo utilizar funciones de agregación para mejorar tus consultas en bases de datos
Cómo optimizar tus consultas SQL para operaciones relacionales eficientes
Optimizar tus consultas SQL es esencial para mejorar el rendimiento de las operaciones relacionales en bases de datos. Una práctica común es utilizar índices, que permiten acceder a los datos de manera más rápida y eficiente. Al crear índices en las columnas que se utilizan frecuentemente en las consultas, se puede reducir significativamente el tiempo de respuesta. Sin embargo, es importante no abusar de ellos, ya que demasiados índices pueden ralentizar las operaciones de escritura.
Otra estrategia efectiva es la reducción de la complejidad de las consultas. Esto se puede lograr mediante la simplificación de las sentencias SQL, evitando subconsultas innecesarias y utilizando uniones en lugar de múltiples selecciones cuando sea posible. Además, agrupar las condiciones en una cláusula WHERE puede facilitar el análisis y mejorar el rendimiento. Aquí hay algunas recomendaciones:
- Evita el uso de SELECT *; especifica las columnas necesarias.
- Utiliza JOIN en lugar de subconsultas cuando sea adecuado.
- Filtra los datos lo más pronto posible en la consulta.
Finalmente, considerar el uso de explain plans puede ser invaluable. Estas herramientas permiten visualizar cómo el motor de la base de datos ejecuta una consulta, ayudando a identificar cuellos de botella y áreas de mejora. Al analizar el plan de ejecución, puedes realizar ajustes estratégicos que optimicen las operaciones relacionales, asegurando que tus consultas sean tanto efectivas como eficientes.
Otro articulo de ayuda: La tecnología de reconocimiento óptico de caracteres transforma la digitalización de documentos
La tecnología de reconocimiento óptico de caracteres transforma la digitalización de documentosLos diferentes tipos de operaciones relacionales en bases de datos: una guía completa
Las operaciones relacionales en bases de datos son fundamentales para la manipulación y recuperación de datos. Entre las más comunes se encuentran la selección, que permite extraer datos específicos de una tabla; la proyección, que se utiliza para obtener solo las columnas deseadas; y la unión, que combina filas de diferentes tablas con estructuras similares. Comprender cómo y cuándo utilizar estas operaciones es esencial para la eficiencia en el manejo de bases de datos.
Además de las operaciones básicas, existen otras técnicas que enriquecen la interacción con los datos. Por ejemplo, la intersección permite obtener los registros que aparecen en ambas tablas, mientras que la diferencia proporciona aquellos registros que están en una tabla pero no en la otra. Estas operaciones son cruciales para realizar análisis complejos y obtener insights valiosos a partir de la información recopilada.
Un aspecto clave en la ejecución de operaciones relacionales es la correcta utilización de JOINs. Estas operaciones permiten combinar datos de dos o más tablas en función de una relación lógica entre ellas. Los tipos de JOIN más utilizados incluyen el INNER JOIN, LEFT JOIN, RIGHT JOIN y FULL OUTER JOIN, cada uno con su propia lógica de combinación. Elegir el tipo correcto de JOIN es vital para garantizar que los resultados sean precisos y relevantes.
Por último, es importante mencionar que las operaciones de agrupamiento y ordenamiento también juegan un papel crucial en la consulta de datos. Utilizando la cláusula GROUP BY, se pueden agrupar registros que comparten ciertas características, y con ORDER BY, se pueden organizar los resultados según criterios específicos. Estas herramientas no solo mejoran la legibilidad de los datos, sino que también permiten una mejor toma de decisiones basada en la información presentada.
Mejores prácticas para realizar uniones (JOIN) en bases de datos
Al realizar uniones (JOIN) en bases de datos, es esencial elegir el tipo de unión correcto para obtener los resultados deseados. Utilizar INNER JOIN cuando se requiere obtener solo registros coincidentes en ambas tablas es una práctica común, mientras que LEFT JOIN es útil para incluir todos los registros de la tabla de la izquierda, incluso aquellos que no tienen coincidencias en la tabla de la derecha. Esto puede ayudar a prevenir la pérdida de datos importantes durante las consultas.
Otra mejor práctica es siempre especificar las condiciones de unión de manera clara y concisa. Esto no solo mejora la legibilidad de la consulta, sino que también puede optimizar el rendimiento. A continuación se presentan algunas recomendaciones clave para realizar uniones efectivas:
- Usa alias para las tablas para hacer las consultas más fáciles de leer.
- Evita uniones innecesarias; revisa si realmente necesitas todos los datos que estás combinando.
- Filtra los datos antes de la unión siempre que sea posible para reducir el volumen de datos procesados.
Además, es recomendable revisar el uso de índices en las columnas que se utilizan para las uniones. Asegurarse de que las columnas de clave primaria y clave foránea estén indexadas puede mejorar significativamente el rendimiento de las consultas. Implementar estas prácticas no solo facilita la gestión de datos, sino que también mejora la eficiencia de las operaciones relacionales en bases de datos.
Errores comunes en operaciones relacionales y cómo evitarlos
Uno de los errores comunes en las operaciones relacionales es la falta de claridad en las condiciones de filtrado. Al no especificar correctamente las condiciones en las cláusulas WHERE, se pueden obtener resultados inesperados o redundantes. Es recomendable revisar y validar las condiciones de filtrado para asegurar que solo se seleccionen los registros relevantes y evitar la sobrecarga de datos innecesarios.
Otro error frecuente es el uso inapropiado de las uniones. A menudo, los desarrolladores pueden optar por uniones que no son necesarias o que generan resultados no deseados. Para evitar esto, es útil implementar prácticas que incluyan la revisión de la necesidad de cada unión y el uso de subconsultas cuando sea más eficiente. De esta manera, se pueden obtener conjuntos de datos más claros y manejables.
Además, la falta de indexación adecuada puede llevar a un rendimiento deficiente en las consultas. No indexar columnas que son frecuentemente usadas en filtros, uniones o agrupamientos puede resultar en tiempos de respuesta lentos. Es importante analizar el uso de índices y determinar cuáles columnas deben ser indexadas, lo que puede mejorar significativamente la eficiencia de las operaciones relacionales.
Por último, no revisar el plan de ejecución de las consultas puede llevar a errores críticos. Este análisis permite identificar cuellos de botella y optimizar el rendimiento de las operaciones. Siempre que ejecutes una consulta, es recomendable analizar el plan para detectar áreas de mejora, garantizando que las operaciones se realicen de manera efectiva y eficiente.
La importancia de índices en operaciones relacionales en bases de datos
La utilización de índices en bases de datos relacionales es crucial para optimizar el rendimiento de las consultas. Los índices actúan como estructuras de datos que mejoran la velocidad de búsqueda al permitir un acceso más rápido a las filas relevantes. Sin ellos, el motor de la base de datos podría tener que realizar una búsqueda completa de la tabla, lo que puede resultar en tiempos de respuesta inaceptables, especialmente en bases de datos grandes. Por lo tanto, implementar índices de manera estratégica puede marcar una diferencia significativa en la eficiencia de las operaciones relacionales.
Además de mejorar la velocidad de consulta, los índices también influyen en el uso de recursos del sistema. Una tabla con índices bien diseñados puede reducir la carga del servidor, ya que minimiza la cantidad de datos que deben ser leídos y procesados durante una operación. Sin embargo, es fundamental encontrar un equilibrio, ya que la creación de demasiados índices puede ralentizar las operaciones de escritura, como inserciones y actualizaciones. Por lo tanto, es esencial evaluar qué columnas requieren índices basándose en patrones de consulta frecuentes.
Existen diferentes tipos de índices, como los índices B-tree y índices hash, cada uno con sus propias ventajas dependiendo del tipo de consulta que se realice. Por ejemplo, los índices B-tree son ideales para consultas de rango, mientras que los índices hash son más eficientes para búsquedas de igualdad. Conocer estos tipos y cuándo utilizarlos puede ser determinante para mejorar la eficacia de las operaciones relacionales en bases de datos. A continuación, se presentan algunas consideraciones sobre los tipos de índices:
- Índices B-tree: Efectivos para consultas que involucran rangos y ordenación.
- Índices hash: Ideales para operaciones de búsqueda exacta.
- Índices compuestos: Útiles cuando las consultas incluyen múltiples columnas.
Por último, es recomendable revisar periódicamente los índices existentes. Con el tiempo, las necesidades de consulta pueden cambiar, y un índice que era útil en el pasado podría volverse innecesario o ineficiente. Herramientas de análisis de rendimiento pueden ayudar a identificar índices que no están siendo utilizados o que tienen un impacto negativo en las operaciones de escritura, permitiendo realizar ajustes que optimicen aún más el rendimiento de las bases de datos relacionales.
Cómo utilizar funciones de agregación para mejorar tus consultas en bases de datos
Las funciones de agregación son herramientas poderosas en SQL que permiten resumir y analizar grandes volúmenes de datos de manera efectiva. Estas funciones, como SUM, AVG, COUNT, MAX y MIN, facilitan la obtención de insights valiosos a partir de los datos almacenados. Al emplear estas funciones, no solo se optimizan las consultas, sino que se mejora la capacidad de toma de decisiones basada en datos concretos y medibles.
Una buena práctica al utilizar funciones de agregación es combinarlas con la cláusula GROUP BY. Esto permite segmentar los datos en grupos antes de aplicar las funciones de agregación, ofreciendo un análisis más detallado. Por ejemplo, si deseas conocer el total de ventas por cada producto, puedes agrupar los resultados por la columna de productos y aplicar la función SUM a la columna de ventas. Aquí, algunas consideraciones importantes:
- Utiliza HAVING para filtrar resultados después de la agregación.
- Asegúrate de entender la diferencia entre COUNT(*) y COUNT(columna).
- Aplica funciones de agregación en combinación con otras cláusulas como JOIN para obtener datos más completos.
Por último, es recomendable analizar el impacto de las funciones de agregación en el rendimiento de las consultas. En ocasiones, el uso excesivo o inadecuado de estas funciones puede llevar a un aumento en el tiempo de ejecución. Por ello, es clave implementar estrategias que incluyan la revisión de los planes de ejecución y la optimización de las consultas que emplean funciones de agregación. De esta forma, se garantiza que tus operaciones relacionales sean no solo efectivas, sino también eficientes.
Iniciar Sesión HBO: Guía Paso a Paso

Cómo darse de baja de DAZN - Guía paso a paso
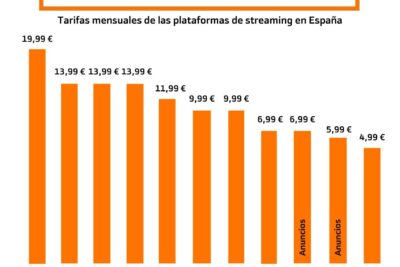
Plataformas Streaming: Comparativa y Precios 2024

Iniciar Sesión Netflix: App, PC o TV

Móviles con Tapa 2023: La Mejor Selección

Manuales de Móviles: Guía Completa
Deja una respuesta
Contenido relacionado