
Cómo utilizar el Análisis de Componentes Principales para la Reducción de Dimensionalidad en Datos
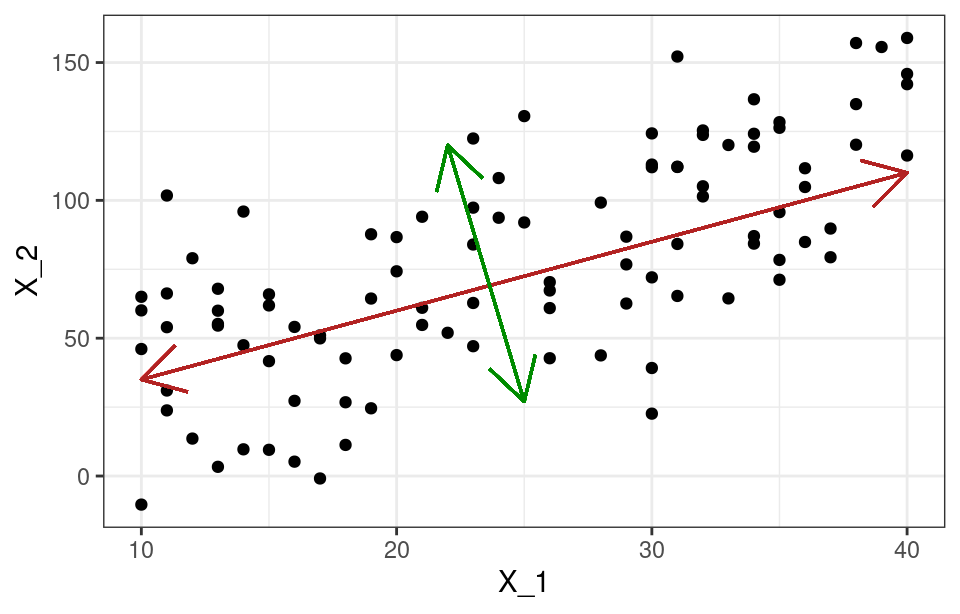
El Análisis de Componentes Principales (PCA, por sus siglas en inglés) es una técnica estadística fundamental que se utiliza para reducir la dimensionalidad de grandes conjuntos de datos, preservando al mismo tiempo la mayor cantidad de información posible. Esta metodología es especialmente útil en el análisis exploratorio de datos y en la preparación de datos para modelos de machine learning, donde la alta dimensionalidad puede complicar el proceso de análisis y visualización.
En este artículo, exploraremos cómo utilizar el Análisis de Componentes Principales para la Reducción de Dimensionalidad en Datos, abordando los pasos clave desde la estandarización de los datos hasta la interpretación de los componentes principales. A través de ejemplos prácticos, demostraremos cómo esta técnica puede facilitar la identificación de patrones y relaciones ocultas en los datos, mejorando así la eficiencia y efectividad del análisis.
Navega por nuestro contenido
- ¿Qué es el Análisis de Componentes Principales y cómo se utiliza en la reducción de dimensionalidad?
- Beneficios del Análisis de Componentes Principales en el manejo de datos complejos
- Paso a paso: Cómo aplicar el Análisis de Componentes Principales en Python
- Errores comunes al implementar el Análisis de Componentes Principales y cómo evitarlos
- Comparativa: Análisis de Componentes Principales vs. otras técnicas de reducción de dimensionalidad
- Interpretación de los resultados del Análisis de Componentes Principales en tus datos
¿Qué es el Análisis de Componentes Principales y cómo se utiliza en la reducción de dimensionalidad?
El Análisis de Componentes Principales (PCA) es una técnica de reducción de dimensionalidad que transforma un conjunto de variables correlacionadas en un conjunto de variables no correlacionadas, denominadas componentes principales. Estos componentes son lineales y están ordenados de tal manera que el primero retiene la mayor parte de la varianza de los datos, seguido por el segundo, y así sucesivamente. Este enfoque permite simplificar el análisis, conservando información clave y minimizando la pérdida de datos importante.
La utilización de PCA se vuelve especialmente relevante en contextos donde la dimensionalidad es elevada, como en el caso de imágenes, datos genómicos o cualquier conjunto de datos con múltiples características. Los pasos típicos para aplicar PCA incluyen:
- Estandarización de los datos.
- Cálculo de la matriz de covarianza.
- Obtención de los vectores y valores propios.
- Selección de los componentes principales según la varianza explicada.
Una de las principales ventajas del PCA es su capacidad para revelar la estructura subyacente de los datos al identificar patrones que pueden no ser evidentes a simple vista. Esto es particularmente útil en análisis exploratorio, donde los investigadores buscan insights que pueden guiar futuras investigaciones o la construcción de modelos predictivos. Además, al reducir la dimensionalidad, se puede mejorar la eficiencia de algoritmos de aprendizaje automático, disminuyendo el tiempo de entrenamiento y aumentando la precisión.
Otro articulo de ayuda: Los Clasificadores y su Importancia en el Análisis de Datos y la Inteligencia Artificial
Los Clasificadores y su Importancia en el Análisis de Datos y la Inteligencia ArtificialEn resumen, el Análisis de Componentes Principales es una herramienta poderosa que transforma y simplifica conjuntos de datos complejos. Su aplicación correcta no solo facilita la visualización de datos, sino que también mejora la robustez de los modelos analíticos. Al adoptar PCA, los analistas pueden concentrarse en las características más relevantes sin perder de vista la esencia de la información contenida en los datos.
Beneficios del Análisis de Componentes Principales en el manejo de datos complejos
Uno de los beneficios más significativos del Análisis de Componentes Principales (PCA) es su capacidad para reducir la complejidad de los datos sin perder información crítica. Al condensar un conjunto de variables en unos pocos componentes principales, los analistas pueden visualizar y comprender mejor la estructura subyacente de los datos. Esto es especialmente útil en conjuntos de datos con alta dimensionalidad, donde la interpretación puede volverse abrumadora.
Además, el PCA ayuda a mejorar la eficiencia de los modelos de aprendizaje automático. Al disminuir el número de características a considerar, se pueden reducir los tiempos de entrenamiento y mejora la capacidad del modelo para generalizar a nuevos datos. Esto se traduce en una menor probabilidad de sobreajuste, lo cual es una preocupación común en modelos complejos con muchas variables.
Otro aspecto importante es la identificación de patrones en los datos. El PCA facilita la detección de relaciones ocultas y correlaciones entre variables que de otro modo pasarían desapercibidas. Esto puede ser crucial en áreas como la investigación biomédica, donde la comprensión de interacciones complejas puede llevar a descubrimientos significativos y nuevas hipótesis.
Finalmente, el uso del PCA permite abordar de manera más efectiva el ruido en los datos. Al enfocarse en las dimensiones que realmente aportan valor y eliminando las que no, se obtiene un conjunto de datos más limpio y manejable, lo cual es esencial para un análisis riguroso. En resumen, el Análisis de Componentes Principales se presenta como una herramienta indispensable en el manejo de datos complejos, optimizando la interpretación y la toma de decisiones informadas.
Paso a paso: Cómo aplicar el Análisis de Componentes Principales en Python
Para aplicar el Análisis de Componentes Principales (PCA) en Python, comenzamos por importar las librerías necesarias. Generalmente, utilizamos NumPy para la manipulación de datos y Matplotlib o Seaborn para la visualización. Además, Scikit-learn es fundamental, ya que ofrece una implementación de PCA que simplifica el proceso. A continuación, podemos seguir estos pasos iniciales:
- Importar las librerías: NumPy, Matplotlib, Seaborn, y Scikit-learn.
- Cargar el conjunto de datos que deseamos analizar.
- Visualizar los datos para entender su estructura inicial.
Una vez que hemos cargado y visualizado los datos, el siguiente paso es estandarizar las características. Esto es crucial, ya que PCA es sensible a la escala de los datos. Utilizamos el StandardScaler de Scikit-learn para transformar los datos y que todas las características tengan una media de 0 y una desviación estándar de 1. Así conseguimos que la reducción de dimensionalidad no se vea sesgada por las diferencias en las escalas de las variables. Los pasos son los siguientes:
- Instanciar el scaler y ajustarlo a los datos.
- Transformar los datos usando el scaler previamente ajustado.
Después de estandarizar los datos, calculamos la matriz de covarianza, que nos permitirá entender cómo varían conjuntamente las diferentes características. A partir de ahí, podemos obtener los vectores y valores propios, que son esenciales para identificar los componentes principales. Este proceso se puede realizar fácilmente con funciones de la librería NumPy. Una vez que tenemos estos elementos, podemos proceder a elegir los componentes principales basados en la varianza explicada. Los pasos son:
- Calcular la matriz de covarianza usando los datos estandarizados.
- Obtener los vectores y valores propios.
- Ordenar los valores propios y seleccionar los vectores correspondientes para los componentes principales deseados.
Errores comunes al implementar el Análisis de Componentes Principales y cómo evitarlos
Uno de los errores más comunes al implementar el Análisis de Componentes Principales (PCA) es no estandarizar los datos antes de la aplicación de la técnica. Dado que PCA es sensible a la escala de las variables, si no se realiza esta estandarización, las características con mayores magnitudes pueden dominar los componentes principales, distorsionando así la interpretación de los resultados. Para evitar este problema, asegúrate de utilizar métodos como el StandardScaler para centrar y escalar los datos adecuadamente.
Otro error frecuente es seleccionar el número incorrecto de componentes principales. Muchas veces, los analistas deciden arbitrariamente cuántos componentes conservar, lo que puede llevar a perder información valiosa o, por el contrario, incluir ruido. Para evitar esto, es recomendable utilizar la varianza explicada como guía, analizando el gráfico de "codo" para identificar el punto donde se estabiliza la varianza acumulada y tomar decisiones informadas sobre la cantidad de componentes a retener.
Además, es crucial no interpretar los componentes principales de forma aislada. Cada componente es una combinación lineal de las variables originales, y su significado puede no ser evidente sin un análisis adicional. Para evitar confusiones, se sugiere realizar un análisis de carga de los componentes, que permite identificar qué variables contribuyen más a cada componente, ofreciendo una visión más completa y contextualizada de los datos.
Finalmente, otro error a evitar es descuidar la validación de los resultados obtenidos a través del PCA. Es importante validar la reducción de dimensionalidad mediante técnicas como la validación cruzada o la evaluación del rendimiento del modelo en datos de prueba. Esto asegura que la reducción de dimensionalidad no compromete la capacidad del modelo para generalizar y que la información crítica se ha mantenido durante el proceso.
Comparativa: Análisis de Componentes Principales vs. otras técnicas de reducción de dimensionalidad
El Análisis de Componentes Principales (PCA) se distingue de otras técnicas de reducción de dimensionalidad, como el Análisis Discriminante Lineal (LDA) o t-SNE, por su enfoque en la varianza máxima. Mientras que PCA busca maximizar la varianza de los datos en componentes no correlacionados, el LDA se enfoca en encontrar la proyección que maximiza la separabilidad entre diferentes clases. Esto hace que PCA sea más generalista, ideal para exploración de datos, mientras que LDA es más efectivo en problemas de clasificación específicos.
Otra técnica común es el uso de autoencoders, una variante de redes neuronales. A diferencia de PCA, que es un enfoque lineal, los autoencoders pueden capturar relaciones no lineales en los datos, lo que puede ser ventajoso en conjuntos de datos complejos. Sin embargo, requieren más datos y un proceso de entrenamiento que a menudo es más intensivo computacionalmente. Así, mientras que PCA proporciona resultados rápidos y fáciles de interpretar, los autoencoders pueden ofrecer una comprensión más profunda cuando se dispone de suficientes recursos.
Al comparar PCA con métodos como el t-SNE, es importante considerar los resultados visuales. t-SNE es particularmente eficaz para visualizar datos de alta dimensión en dos o tres dimensiones, preservando las relaciones locales entre los puntos. Sin embargo, este método no es adecuado para la reducción de dimensionalidad en la preparación de datos para modelos predictivos, ya que no se puede revertir fácilmente. Por el contrario, los componentes principales obtenidos a través de PCA son más fáciles de interpretar y utilizar en modelos posteriores, lo que puede ser crucial en aplicaciones de aprendizaje automático.
En términos de tiempo de computación, PCA suele ser más eficiente en comparación con técnicas como UMAP y t-SNE, que son más complejas y pueden requerir ajustes finos de parámetros. Esto permite que PCA se aplique de manera efectiva en escenarios donde la velocidad es importante, como en aplicaciones de procesamiento en tiempo real. En resumen, la elección de la técnica de reducción de dimensionalidad adecuada depende del problema específico y de la naturaleza de los datos, y PCA ofrece una opción robusta y confiable para una amplia gama de aplicaciones.
Interpretación de los resultados del Análisis de Componentes Principales en tus datos
La interpretación de los resultados del Análisis de Componentes Principales es fundamental para extraer insights valiosos de los datos. Los componentes principales representan nuevas dimensiones que combinan la información de las variables originales, y su análisis puede revelar patrones significativos. Al observar el gráfico de varianza explicada, se puede determinar cuánta información retiene cada componente, facilitando la selección de aquellos que aportan mayor valor a la interpretación global.
Una vez seleccionados los componentes, es útil realizar un análisis de carga para entender cómo cada variable contribuye a los componentes principales. Este análisis permite identificar las variables más influyentes y su relación con los nuevos ejes. Por ejemplo, si el primer componente está fuertemente correlacionado con ciertas características, esto puede indicar que esas variables son fundamentales para comprender el fenómeno estudiado. A continuación se presenta un ejemplo de tabla de cargas:
| Componente | Variable 1 | Variable 2 | Variable 3 |
|---|---|---|---|
| Componente 1 | 0.8 | 0.5 | 0.2 |
| Componente 2 | 0.1 | 0.7 | 0.6 |
Además, la proyección de los datos originales en los componentes principales permite visualizar cómo se distribuyen las observaciones en el nuevo espacio reducido. Esta visualización es clave para detectar clústeres o agrupaciones de datos, así como para identificar posibles outliers. Utilizar gráficos de dispersión de los primeros dos o tres componentes puede facilitar la comprensión de la estructura de los datos y guiar decisiones adicionales en el análisis.
Por último, es importante considerar que la interpretación de los resultados va más allá de los números. A menudo, se requiere un contexto adicional para comprender totalmente el significado de los componentes. La combinación de conocimientos del dominio con los resultados del PCA puede ayudar a generar hipótesis y fomentar descubrimientos que impulsan la investigación futura. Así, la interpretación efectiva de los resultados del Análisis de Componentes Principales es un paso crítico hacia una comprensión más profunda de los datos analizados.
Iniciar Sesión HBO: Guía Paso a Paso

Cómo darse de baja de DAZN - Guía paso a paso
Plataformas Streaming: Comparativa y Precios 2024

Iniciar Sesión Netflix: App, PC o TV

Móviles con Tapa 2023: La Mejor Selección

Manuales de Móviles: Guía Completa
Deja una respuesta
Contenido relacionado