
El algoritmo KNN y su aplicación en el análisis de datos
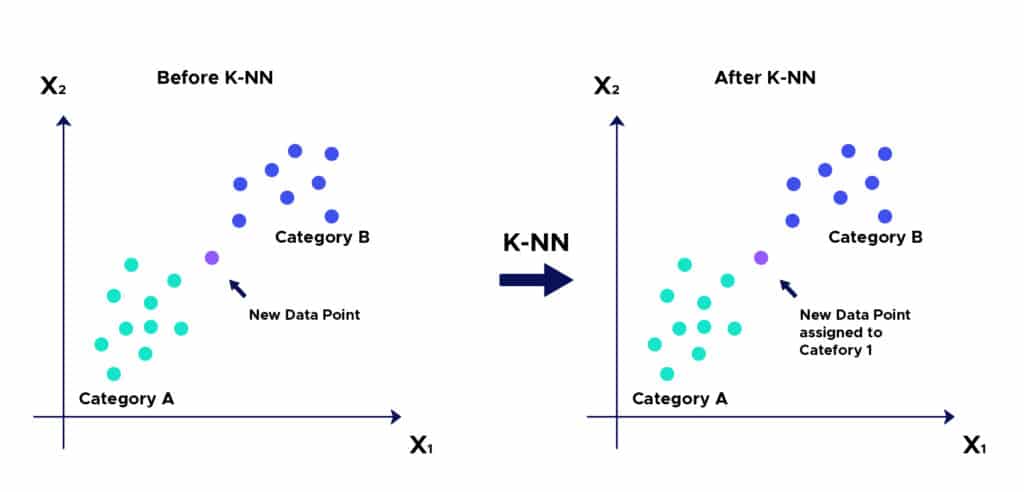
El algoritmo KNN, que significa K-Nearest Neighbors, es una técnica de aprendizaje supervisado que se utiliza para clasificación y regresión. Este método se basa en la idea de que los datos similares se encuentran cerca unos de otros en el espacio de características, lo cual lo convierte en una herramienta efectiva para diversos problemas de análisis de datos.
En el contexto actual, donde la cantidad de datos generados es abrumadora, el algoritmo KNN y su aplicación en el análisis de datos se ha vuelto fundamental para extraer patrones y realizar predicciones precisas. Su simplicidad y facilidad de implementación lo hacen atractivo tanto para investigadores como para profesionales en el campo de la ciencia de datos.
Navega por nuestro contenido
- Introducción al algoritmo KNN y su relevancia en el análisis de datos
- Cómo funciona el algoritmo KNN: Principios y fundamentos
- Aplicaciones prácticas del algoritmo KNN en el análisis de datos
- Ventajas y desventajas del algoritmo KNN en la clasificación de datos
- Comparativa entre KNN y otros algoritmos de análisis de datos
- Mejores prácticas para implementar el algoritmo KNN en proyectos de análisis de datos
Introducción al algoritmo KNN y su relevancia en el análisis de datos
El algoritmo KNN se fundamenta en el principio de que un objeto se asemeja más a sus vecinos más cercanos que a aquellos que están más alejados. Esta característica lo convierte en una herramienta poderosa dentro del análisis de datos, ya que permite clasificar y predecir resultados en contextos donde las relaciones entre las variables no son lineales. Su implementación es especialmente útil en áreas como la detección de fraudes, reconocimiento de patrones y análisis de sentimientos.
Uno de los aspectos más relevantes del KNN es su capacidad de adaptarse a diferentes tipos de datos. Esto se debe a que no requiere suposiciones estrictas sobre la distribución de los datos. A continuación, se presentan algunas de sus aplicaciones más comunes:
- Clasificación de imágenes y reconocimiento facial.
- Filtrado colaborativo en sistemas de recomendación.
- Diagnóstico médico basado en síntomas previos.
Además, el algoritmo KNN es fácil de entender y de implementar, lo que lo hace accesible para quienes comienzan en el campo del análisis de datos. Sin embargo, es importante considerar algunos de sus desafíos, tales como la eficiencia computacional y la elección del valor de K, que puede influir significativamente en los resultados. En la siguiente tabla se presenta una comparación entre KNN y otros algoritmos de clasificación:
Otro articulo de ayuda: El arte y la ciencia del data mining para la toma de decisiones informadas
El arte y la ciencia del data mining para la toma de decisiones informadas| Algoritmo | Ventajas | Desventajas |
|---|---|---|
| KNN | Sencillo y efectivo para datos no lineales | Requiere mucha memoria y es lento en grandes conjuntos de datos |
| Árboles de decisión | Interpretabilidad alta | Puede sobreajustar con datos ruidosos |
| Máquinas de soporte vectorial | Alta precisión en clasificación | Difícil de implementar en datos grandes |
En conclusión, el algoritmo KNN sigue siendo una opción relevante en el análisis de datos debido a su flexibilidad y facilidad de uso. Aunque presenta ciertas limitaciones, su aplicación en diversas industrias demuestra su eficacia como herramienta de análisis y predicción. A medida que avanza la tecnología, el KNN continúa evolucionando, adaptándose a nuevas necesidades y desafíos en un mundo cada vez más orientado a los datos.
Cómo funciona el algoritmo KNN: Principios y fundamentos
El algoritmo KNN funciona a partir del cálculo de la distancia entre un punto de datos nuevo y los puntos de datos existentes en el conjunto de entrenamiento. Este cálculo se realiza utilizando diversas métricas, siendo la más común la distancia euclidiana. Una vez que se han calculado las distancias, el algoritmo selecciona los K vecinos más cercanos para determinar la clase o el valor del nuevo punto, basándose en la mayoría de las etiquetas de los vecinos o en el promedio de sus valores.
El valor de K es crucial en el funcionamiento del KNN, ya que influye directamente en la precisión de las predicciones. Un K bajo puede hacer que el modelo sea sensible al ruido en los datos, lo que podría llevar a clasificaciones erróneas. Por otro lado, un K demasiado alto puede diluir la influencia de los vecinos más cercanos, haciendo que el modelo sea menos efectivo. Por lo tanto, se recomienda realizar una validación cruzada para escoger el mejor valor de K antes de aplicar el algoritmo.
La implementación del algoritmo KNN se caracteriza por su simplicidad. No requiere un entrenamiento explícito, ya que todos los cálculos se realizan en el momento de la predicción. Esto significa que, aunque es fácil de aplicar, la eficiencia computacional puede verse comprometida, especialmente con grandes volúmenes de datos. A medida que el tamaño del conjunto de datos aumenta, el tiempo necesario para calcular las distancias puede crecer exponencialmente, haciendo que el algoritmo se vuelva lento.
Finalmente, el rendimiento del KNN puede verse influenciado por la escala de los datos. Es fundamental normalizar o estandarizar las características antes de aplicar el algoritmo, ya que las variables con diferentes escalas pueden dominar el cálculo de la distancia. Este paso de preprocesamiento ayuda a mejorar la precisión del modelo y asegura que cada característica contribuya equitativamente al análisis de datos.
Aplicaciones prácticas del algoritmo KNN en el análisis de datos
El algoritmo KNN se utiliza en diversas aplicaciones prácticas que demuestran su versatilidad en el análisis de datos. Entre estas aplicaciones, la clasificación de textos se destaca, donde KNN ayuda a categorizar documentos en función de su contenido, facilitando así la organización y búsqueda de información. Otras áreas incluyen:
- Clasificación de correos electrónicos como spam o no spam.
- Análisis de sentimientos en redes sociales.
- Detección de fraudes en transacciones financieras.
Otro campo donde el KNN demuestra su eficacia es en la medicina, particularmente en el diagnóstico de enfermedades. Al analizar datos de pacientes y sus síntomas previos, el algoritmo puede predecir condiciones médicas basándose en la similitud con casos anteriores, proporcionando así un apoyo valioso para los profesionales de la salud. Este uso resalta la importancia del KNN en:
- Diagnóstico temprano de enfermedades.
- Personalización de tratamientos médicos.
- Evaluación de riesgos en salud pública.
En el ámbito del comercio electrónico, el KNN se aplica en sistemas de recomendación. Utilizando datos de comportamiento de usuarios, este algoritmo sugiere productos que podrían interesar a los clientes, mejorando la experiencia del usuario y aumentando las ventas. Las aplicaciones en este contexto incluyen:
- Recomendaciones personalizadas de productos.
- Segmentación de clientes para campañas de marketing.
- Optimización de precios según el comportamiento del consumidor.
Finalmente, el KNN también ha encontrado un lugar en el ámbito de la imagen y el video, donde se utiliza para tareas como el reconocimiento facial y la clasificación de imágenes. Gracias a su capacidad para manejar datos visuales complejos, es fundamental en aplicaciones como:
- Seguridad y vigilancia mediante reconocimiento facial.
- Filtrado y organización de grandes bibliotecas de imágenes.
- Mejoras en la realidad aumentada y virtual.
Ventajas y desventajas del algoritmo KNN en la clasificación de datos
El algoritmo KNN presenta varias ventajas que lo hacen atractivo para la clasificación de datos. Una de las principales es su simplicidad y facilidad de implementación, lo que permite a los principiantes en análisis de datos utilizarlo sin complicaciones. Además, KNN es adaptable a diferentes tipos de datos y no requiere suposiciones sobre su distribución, lo que lo convierte en una opción versátil para resolver problemas en contextos variados.
Sin embargo, el KNN también tiene desventajas que es importante considerar. Por ejemplo, su rendimiento puede verse afectado por la cantidad de datos, ya que el algoritmo requiere calcular las distancias entre todos los puntos de datos, lo que puede resultar en una alta demanda de recursos computacionales. Asimismo, la elección del valor de K es crucial; un K inadecuado puede llevar a resultados poco precisos, ya que puede ser sensible al ruido o diluir la influencia de los vecinos más relevantes.
Otro desafío del algoritmo KNN es su dependencia de la escala de los datos. Si las características no están normalizadas, algunas variables pueden dominar el cálculo de la distancia, afectando negativamente la precisión del modelo. Por lo tanto, es fundamental realizar un preprocesamiento adecuado antes de aplicar KNN, asegurando que todas las características tengan la misma importancia en el análisis.
En resumen, aunque el algoritmo KNN ofrece una serie de beneficios en el análisis de datos, también presenta limitaciones que deben ser abordadas para garantizar resultados precisos. Su idoneidad depende del contexto en el que se aplique y de cómo se manejen los datos, lo que resalta la importancia de una correcta preparación y evaluación en su uso.
Comparativa entre KNN y otros algoritmos de análisis de datos
Al comparar el algoritmo KNN con otros algoritmos de análisis de datos, es esencial considerar la naturaleza de las tareas a realizar. A diferencia de algoritmos como las máquinas de soporte vectorial, que son más efectivas en espacios de alta dimensión, KNN brilla en conjuntos de datos más simples donde se busca una clasificación intuitiva basada en la cercanía. Sin embargo, KNN puede ser menos eficiente en términos de tiempo de computación, especialmente con conjuntos de datos grandes, ya que requiere calcular distancias para todos los puntos, lo que puede ser una desventaja significativa frente a métodos más robustos.
Otro punto de comparación relevante es la interpretabilidad. Mientras que KNN permite una comprensión directa del proceso de toma de decisiones al basarse en ejemplos cercanos, otros algoritmos, como las redes neuronales, pueden actuar como "cajas negras". Esto puede dificultar la comprensión de cómo se llegan a ciertas conclusiones, lo que es crítico en campos como la medicina o la justicia, donde la transparencia es fundamental. Por lo tanto, la elección del algoritmo puede depender de la necesidad de explicaciones claras en los resultados.
En términos de flexibilidad, KNN se adapta fácilmente a diferentes tipos de datos y no requiere suposiciones sobre su distribución, a diferencia de algoritmos como la regresión logística, que asume una relación lineal entre variables. Sin embargo, esto puede ser un arma de doble filo. Aunque KNN es versátil, su rendimiento puede deteriorarse en presencia de datos ruidosos o irrelevantes, lo que no ocurre necesariamente con otros métodos que pueden manejar mejor la variabilidad en los datos.
Finalmente, es importante considerar el impacto del preprocesamiento de datos. Mientras que KNN necesita que los datos estén normalizados para evitar que características con escalas diferentes influyan desproporcionadamente en los resultados, otros algoritmos, como los árboles de decisión, son menos sensibles a la escala. Por lo tanto, en un contexto donde los datos no estén adecuadamente preparados, KNN podría no ser la opción más adecuada en comparación con métodos que pueden funcionar bien con datos crudos.
Mejores prácticas para implementar el algoritmo KNN en proyectos de análisis de datos
Implementar el algoritmo KNN de manera efectiva requiere una cuidadosa selección del valor de K. Es recomendable realizar un análisis de validación cruzada para determinar el valor óptimo de K que minimice el error de predicción. Un K demasiado pequeño puede llevar a sobreajuste, mientras que uno excesivamente grande puede generalizar demasiado y perder detalles importantes en los datos. Por lo tanto, ajustar K debe ser uno de los primeros pasos en el proceso de implementación.
Además, es crucial realizar un preprocesamiento adecuado de los datos antes de aplicar el algoritmo KNN. Esto incluye la normalización o estandarización de las características. Sin un preprocesamiento adecuado, las variables con escalas diferentes pueden dominar el cálculo de la distancia, afectando significativamente la precisión del modelo. Asegúrate de que todas las variables contribuyan de manera equitativa en el análisis.
Otro aspecto a considerar es la reducción de la dimensionalidad si se trabaja con conjuntos de datos con muchas características. Herramientas como el Análisis de Componentes Principales (PCA) pueden ser útiles para simplificar el modelo y mejorar la velocidad de cálculo del KNN, manteniendo al mismo tiempo la calidad de la información. Al reducir las dimensiones, se facilita el cálculo de distancias y se minimiza el riesgo de sobreajuste.
Por último, es recomendable implementar técnicas de optimización como el uso de estructuras de datos eficientes, como árboles de búsqueda de vecinos más cercanos, para acelerar el proceso de búsqueda de los vecinos. Esto puede ser especialmente útil cuando se trabaja con conjuntos de datos grandes, donde el tiempo de respuesta del algoritmo KNN puede ser un factor crítico. Mantener la eficiencia computacional asegura que el análisis de datos se realice de manera efectiva y en tiempos razonables.
Iniciar Sesión HBO: Guía Paso a Paso

Cómo darse de baja de DAZN - Guía paso a paso
Plataformas Streaming: Comparativa y Precios 2024

Iniciar Sesión Netflix: App, PC o TV

Móviles con Tapa 2023: La Mejor Selección

Manuales de Móviles: Guía Completa
Deja una respuesta
Contenido relacionado