
El aprendizaje no supervisado es una técnica fundamental para el análisis de datos

En un mundo donde la cantidad de datos generados crece de manera exponencial, las técnicas de análisis que permiten extraer información significativa se vuelven esenciales. Entre estas, el aprendizaje no supervisado es una técnica fundamental para el análisis de datos, ya que facilita la identificación de patrones y estructuras ocultas sin necesidad de etiquetas previas.
Este enfoque es particularmente valioso en situaciones donde la clasificación de datos es complicada o costosa. Al permitir que los algoritmos exploren y agrupen datos de manera autónoma, el aprendizaje no supervisado abre nuevas oportunidades para comprender mejor los fenómenos complejos que nos rodean.
Navega por nuestro contenido
- El aprendizaje no supervisado: Definición y conceptos clave
- Tipos de algoritmos en el aprendizaje no supervisado
- Aplicaciones del aprendizaje no supervisado en el análisis de datos
- Ventajas del aprendizaje no supervisado en la minería de datos
- Cómo implementar técnicas de aprendizaje no supervisado en proyectos reales
- Desafíos y limitaciones del aprendizaje no supervisado en el análisis de datos
El aprendizaje no supervisado: Definición y conceptos clave
El aprendizaje no supervisado se refiere a un conjunto de técnicas de análisis de datos que permiten identificar patrones y estructuras en conjuntos de datos sin la necesidad de contar con etiquetas o categorías predefinidas. A través de este enfoque, los algoritmos pueden explorar datos de forma autónoma, encontrando similitudes y diferencias que podrían no ser evidentes a simple vista. Este tipo de aprendizaje es especialmente útil en contextos donde la información es escasa o difícil de clasificar.
Entre los conceptos clave del aprendizaje no supervisado, encontramos la agrupación (clustering) y la reducción de dimensionalidad. La agrupación consiste en organizar datos en grupos basados en características comunes, mientras que la reducción de dimensionalidad busca simplificar los datos manteniendo su información esencial. Estas técnicas permiten manejar grandes volúmenes de datos de forma eficiente.
- Agrupación: Identifica grupos dentro de los datos.
- Reducción de dimensionalidad: Simplifica datos complejos.
- Detección de anomalías: Encuentra valores atípicos en los datos.
Finalmente, el aprendizaje no supervisado también se aplica en la minería de datos y el análisis exploratorio, donde se busca descubrir información oculta sin tener hipótesis previas. Esto permite a los investigadores y analistas formular nuevas preguntas y enfoques, convirtiéndolo en una herramienta poderosa para el análisis de datos en diversas disciplinas.
Otro articulo de ayuda: Qué es una API Interfaz de Programación de Aplicaciones y su Importancia en el Desarrollo de Software
Qué es una API Interfaz de Programación de Aplicaciones y su Importancia en el Desarrollo de SoftwareTipos de algoritmos en el aprendizaje no supervisado
Dentro del aprendizaje no supervisado, existen varios tipos de algoritmos que se utilizan para diferentes propósitos. Estos algoritmos son fundamentales para extraer patrones y estructuras de los datos sin necesidad de etiquetas. Entre ellos, destacan principalmente los algoritmos de agrupación y reducción de dimensionalidad, cada uno con aplicaciones específicas en el análisis de datos.
Los algoritmos de agrupación buscan organizar los datos en grupos basados en similitudes. Algunos de los más conocidos incluyen:
- K-means: Asigna datos a k grupos, minimizando la distancia entre los puntos y el centroide del grupo.
- DBSCAN: Identifica grupos basados en la densidad de puntos en el espacio, siendo efectivo para detectar formaciones arbitrarias.
- Hierarchical Clustering: Crea un árbol de jerarquías que muestra cómo se agrupan los datos en diferentes niveles.
Por otro lado, los algoritmos de reducción de dimensionalidad son utilizados para simplificar conjuntos de datos complejos, facilitando su visualización y análisis. Entre estos, encontramos:
- PCA (Análisis de Componentes Principales): Transforma los datos a un nuevo sistema de coordenadas, maximizando la varianza.
- t-SNE: Permite la visualización de datos en menos dimensiones, preservando la estructura local de los datos.
Finalmente, también se encuentran algoritmos para detección de anomalías, que ayudan a identificar valores atípicos en los datos, lo que puede ser crucial para diversas aplicaciones, como la detección de fraudes o el monitoreo de sistemas. En conjunto, estos algoritmos constituyen herramientas clave en el aprendizaje no supervisado y permiten a los analistas descubrir información valiosa en grandes volúmenes de datos.
Aplicaciones del aprendizaje no supervisado en el análisis de datos
El aprendizaje no supervisado tiene una amplia gama de aplicaciones en el análisis de datos, que van desde el marketing hasta la biología. Esta técnica permite a las empresas segmentar a sus clientes en grupos específicos basados en comportamientos y preferencias, lo que mejora la personalización de sus estrategias. Algunas de las aplicaciones más destacadas incluyen:
- Segmentación de mercado: Identificación de distintos grupos de consumidores para dirigir campañas más efectivas.
- Recomendaciones de productos: Sugerencias personalizadas basadas en patrones de compra.
- Análisis de textos: Agrupamiento de documentos similares para facilitar la gestión de información.
En el ámbito de la salud, el aprendizaje no supervisado es fundamental para el análisis de datos clínicos. Permite agrupar pacientes con síntomas similares y descubrir nuevas subcategorías de enfermedades. Algunas aplicaciones en este sector incluyen:
- Detección de enfermedades: Identificación de patrones que pueden indicar condiciones médicas específicas.
- Personalización de tratamientos: Agrupación de pacientes para obtener tratamientos más efectivos según sus características.
- Investigación genómica: Análisis de datos genéticos para descubrir relaciones ocultas entre genes y enfermedades.
Además, el aprendizaje no supervisado se utiliza en la industria financiera para la detección de fraudes. La identificación de patrones inusuales en transacciones puede ayudar a prevenir actividades fraudulentas. Algunas de las aplicaciones incluyen:
- Monitoreo de transacciones: Detección de anomalías en tiempo real para prevenir fraudes.
- Evaluación de riesgos: Agrupación de perfiles de riesgo basados en el comportamiento financiero.
Por último, en el campo de la inteligencia artificial, el aprendizaje no supervisado juega un papel crucial en la mejora de algoritmos de visión por computadora. Esta técnica permite a los sistemas aprender de grandes volúmenes de imágenes y clasificar objetos sin intervención humana. Ejemplos de aplicaciones incluyen:
- Clasificación de imágenes: Agrupación de imágenes similares para facilitar la búsqueda.
- Reconocimiento de patrones: Identificación de objetos en diferentes contextos y condiciones.
Ventajas del aprendizaje no supervisado en la minería de datos
Una de las principales ventajas del aprendizaje no supervisado en la minería de datos es su capacidad para descubrir patrones ocultos que no son evidentes a simple vista. Esto permite a los analistas obtener insights valiosos a partir de grandes volúmenes de datos, lo que resulta fundamental para la toma de decisiones informadas. Al no depender de etiquetas, se eliminan sesgos que podrían influir en los resultados, proporcionando una visión más objetiva de la información.
Además, el aprendizaje no supervisado es altamente eficiente en la reducción de costos asociados a la preparación de datos. En entornos donde la etiquetación manual es laboriosa y costosa, esta técnica ofrece una alternativa viable. Al permitir que los algoritmos aprendan sin intervención humana, se acelera el proceso de análisis y se aprovechan recursos de manera más efectiva.
Otra ventaja significativa es su capacidad para adaptarse a cambios en los datos. A medida que se generan nuevos datos, los modelos de aprendizaje no supervisado pueden ajustarse y aprender de manera continua. Esto es especialmente útil en sectores como el marketing y la salud, donde las tendencias y características de los datos pueden cambiar rápidamente, permitiendo una mejora constante en la precisión de los análisis y predicciones.
Finalmente, el aprendizaje no supervisado facilita la exploración de datos en escenarios desconocidos. Al no requerir hipótesis previas, los analistas pueden descubrir relaciones inesperadas y formular nuevas preguntas de investigación. Esta flexibilidad es esencial en áreas como la investigación científica y el desarrollo de nuevos productos, donde la innovación depende de la capacidad para encontrar conexiones que no habían sido consideradas anteriormente.
Cómo implementar técnicas de aprendizaje no supervisado en proyectos reales
Para implementar técnicas de aprendizaje no supervisado en proyectos reales, es fundamental comenzar con una clara definición del problema que se desea resolver. Esto implica identificar qué tipo de patrones o estructuras se están buscando dentro de los datos. Una vez definido el objetivo, se puede proceder a la recopilación y preparación de los datos, asegurando que sean de calidad y estén limpios, lo que facilitará el análisis posterior.
El siguiente paso es elegir el algoritmo adecuado según el tipo de análisis que se desea realizar. Existen diversas técnicas en aprendizaje no supervisado, como la agrupación y la reducción de dimensionalidad. Por ejemplo, si se busca segmentar clientes, algoritmos como K-means o DBSCAN son opciones viables. En cambio, si el objetivo es simplificar datos complejos, PCA o t-SNE son más apropiados. Es recomendable realizar una prueba de varios algoritmos para determinar cuál ofrece los mejores resultados en el contexto específico del proyecto.
Una vez seleccionado el algoritmo, se debe proceder a entrenar el modelo con los datos preparados. Durante esta fase, es esencial monitorear el rendimiento y ajustar los parámetros del modelo según sea necesario. Esto podría incluir la validación de resultados a través de métodos como la visualización de datos o la comparación con resultados esperados, lo que permitirá validar la efectividad de las técnicas aplicadas y realizar ajustes en caso de ser necesario.
Finalmente, la implementación de técnicas de aprendizaje no supervisado debe incluir un plan para la interpretación y comunicación de los resultados obtenidos. Presentar los hallazgos de manera clara y accesible a todas las partes interesadas es crucial para que se tomen decisiones informadas. Además, se deben considerar estrategias para el mantenimiento y actualización del modelo, asegurando que se adapte a los cambios en los datos y continúe ofreciendo valor a lo largo del tiempo.
Desafíos y limitaciones del aprendizaje no supervisado en el análisis de datos
El aprendizaje no supervisado enfrenta varios desafíos que pueden limitar su efectividad en el análisis de datos. Uno de los principales obstáculos es la interpretación de resultados, ya que los patrones detectados por los algoritmos pueden ser difíciles de entender sin un contexto adecuado. Esto puede llevar a conclusiones erróneas si no se complementan con un análisis exhaustivo de la naturaleza de los datos.
Además, la selección de características es un factor crítico en el aprendizaje no supervisado. Si las variables elegidas no son relevantes o están sesgadas, los resultados obtenidos pueden no reflejar la realidad. Es fundamental contar con un proceso de preprocesamiento robusto que garantice la calidad de los datos, lo que incluye la normalización y eliminación de outliers que puedan distorsionar los grupos formados.
Otro desafío importante es el escogido del número de grupos o clusters en técnicas como K-means. Elegir un número inapropiado puede resultar en agrupaciones que no representan la estructura subyacente de los datos. Para abordar este problema, se pueden utilizar técnicas como el método del codo o la validación cruzada para determinar el número óptimo de clusters.
Finalmente, la escalabilidad también es un aspecto a considerar. A medida que los volúmenes de datos crecen, algunos algoritmos de aprendizaje no supervisado pueden volverse ineficientes y requerir un tiempo de procesamiento considerable. Es esencial elegir algoritmos que se adapten a grandes conjuntos de datos sin sacrificar la calidad de los resultados, garantizando así que el análisis sea práctico y útil.
Iniciar Sesión HBO: Guía Paso a Paso

Cómo darse de baja de DAZN - Guía paso a paso
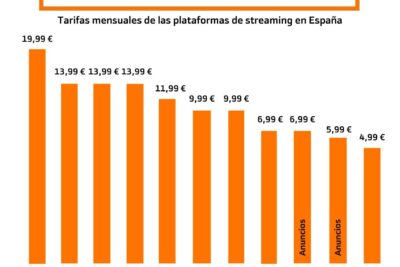
Plataformas Streaming: Comparativa y Precios 2024

Iniciar Sesión Netflix: App, PC o TV

Móviles con Tapa 2023: La Mejor Selección

Manuales de Móviles: Guía Completa
Deja una respuesta
Contenido relacionado