
El uso del modelo de Random Forest en el aprendizaje automático y su aplicación en la ciencia de datos
El aprendizaje automático ha revolucionado la manera en que se procesan y analizan grandes volúmenes de datos, permitiendo descubrir patrones y tendencias ocultas. Entre las diversas técnicas disponibles, el modelo de Random Forest se destaca por su versatilidad y robustez, adaptándose a una amplia gama de problemas de clasificación y regresión.
En este contexto, el uso del modelo de Random Forest en el aprendizaje automático y su aplicación en la ciencia de datos se ha convertido en una herramienta clave para profesionales que buscan optimizar la toma de decisiones basadas en datos. Su capacidad para manejar datos faltantes y su resistencia al sobreajuste lo hacen ideal para análisis complejos en diversas disciplinas, desde la biología hasta la economía.
Navega por nuestro contenido
- Introducción al modelo de Random Forest en el aprendizaje automático
- Beneficios del uso de Random Forest en la ciencia de datos
- Cómo funciona el modelo de Random Forest: una explicación técnica
- Aplicaciones prácticas de Random Forest en la ciencia de datos
- Comparación entre Random Forest y otros algoritmos de aprendizaje automático
- Mejores prácticas para implementar Random Forest en proyectos de ciencia de datos
Introducción al modelo de Random Forest en el aprendizaje automático
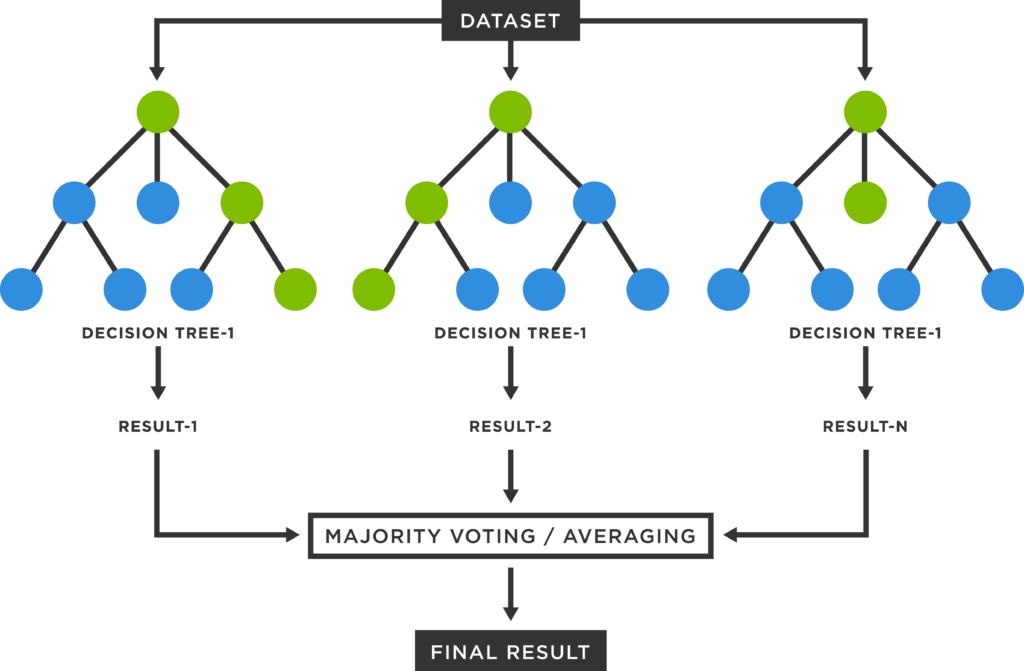
El modelo de Random Forest se basa en la creación de múltiples árboles de decisión que trabajan de manera conjunta para mejorar la precisión de las predicciones. Este enfoque ensemble permite que cada árbol aprenda de una muestra aleatoria del conjunto de datos, lo que ayuda a capturar diferentes patrones y reducir la varianza del modelo final. Dicha técnica es especialmente útil en situaciones donde los datos son ruidosos o tienen muchas características, ya que proporciona una robustez superior frente a otros modelos más simples.
Otra de las ventajas destacadas del modelo de Random Forest es su capacidad para manejar tanto datos categóricos como continuos. Esto se traduce en una gran flexibilidad para abordar problemas de regresión y clasificación. Además, el algoritmo puede calcular la importancia de las variables, lo que permite identificar qué características son más relevantes para el modelo. Este aspecto es crucial en la ciencia de datos, ya que facilita la interpretación de los resultados y ayuda en la selección de variables clave.
El proceso de entrenamiento del modelo de Random Forest implica varios pasos fundamentales, que podemos resumir en la siguiente lista:
Otro articulo de ayuda: Guía Completa sobre Proveedores para Negocios Exitosos
Guía Completa sobre Proveedores para Negocios Exitosos- Muestreo aleatorio de datos para crear árboles de decisión.
- Construcción de cada árbol utilizando un subconjunto de características.
- Predicción a partir del voto mayoritario de los árboles (en clasificación) o promedio de las predicciones (en regresión).
- Evaluación del modelo utilizando métricas de rendimiento adecuadas.
En resumen, el modelo de Random Forest se ha convertido en un componente esencial del aprendizaje automático, ofreciendo un equilibrio entre precisión y facilidad de uso. Su adaptabilidad y robustez lo han llevado a ser utilizado en diversas aplicaciones, desde la detección de fraudes hasta el análisis de imágenes médicas. Por lo tanto, comprender su funcionamiento y aplicaciones es fundamental para cualquier profesional en el campo de la ciencia de datos.
Beneficios del uso de Random Forest en la ciencia de datos
El modelo de Random Forest ofrece varios beneficios significativos en el ámbito de la ciencia de datos, destacando su capacidad para manejar grandes volúmenes de datos con eficacia. Uno de sus principales atributos es su resistencia al sobreajuste, lo cual es crucial cuando se trabaja con conjuntos de datos complejos. Esto permite que los modelos generados sean más generalizables y, por lo tanto, más precisos en predicciones futuras.
Otro beneficio importante es la importancia de características que el modelo puede calcular. A través de este análisis, los científicos de datos pueden identificar las variables más relevantes que contribuyen a las predicciones, lo que facilita la comprensión del problema en cuestión y permite una mejor toma de decisiones. Esta capacidad es especialmente valiosa en áreas como la biomedicina, donde la selección de variables puede influir en diagnósticos y tratamientos.
Además, el modelo de Random Forest es altamente escalable y se adapta fácilmente a conjuntos de datos de diferentes tamaños y estructuras. Esto lo convierte en una opción ideal para aplicaciones en big data, donde la variedad y la cantidad de datos pueden ser un desafío. Su rendimiento se mantiene eficiente sin importar la complejidad del conjunto de datos, lo que brinda confianza a los analistas en su uso.
Por último, el modelo también se caracteriza por su facilidad de uso. Con un mínimo de ajuste de hiperparámetros, los usuarios pueden implementar el modelo y obtener resultados satisfactorios rápidamente. Esto no solo acelera el proceso de análisis de datos, sino que también permite que más profesionales, independientemente de su nivel de experiencia, se beneficien de las técnicas de aprendizaje automático sin requerir un profundo conocimiento técnico.
Cómo funciona el modelo de Random Forest: una explicación técnica
El modelo de Random Forest funciona mediante la creación de un conjunto de árboles de decisión, cada uno de los cuales toma decisiones basadas en un subconjunto aleatorio de datos y características. Esta diversidad en la construcción de los árboles permite que el modelo generalice mejor y reduzca el riesgo de sobreajuste, especialmente en datos complejos o ruidosos. Al final, las predicciones del modelo se obtienen a través de un proceso de votación mayoritaria (en clasificación) o promediando los resultados (en regresión).
El entrenamiento del modelo de Random Forest implica varios pasos cruciales, que se pueden resumir en la siguiente lista:
- Seleccionar aleatoriamente muestras del conjunto de datos original.
- Construir árboles de decisión en cada muestra utilizando un subconjunto aleatorio de características.
- Realizar predicciones mediante el consenso de todos los árboles construidos.
- Evaluar el rendimiento del modelo utilizando técnicas de validación cruzada.
Una característica importante del modelo es su capacidad para estimar la importancia de las variables. Esto se logra analizando la disminución del rendimiento del modelo cuando se permutan las variables de entrada. Este enfoque no solo ayuda a identificar las características más influyentes, sino que también se traduce en un modelo más interpretable, lo que resulta esencial en el campo de la ciencia de datos.
Por último, es importante mencionar que Random Forest ofrece robustez ante la multicolinealidad, un fenómeno común en conjuntos de datos donde las variables están altamente correlacionadas. Debido a su naturaleza de ensamblaje, el modelo puede manejar la redundancia de las variables sin afectar significativamente su rendimiento, lo que lo convierte en una herramienta invaluable para problemas complejos en la analítica de datos.
Aplicaciones prácticas de Random Forest en la ciencia de datos
El modelo de Random Forest se ha convertido en una herramienta valiosa en diversas aplicaciones prácticas dentro de la ciencia de datos. En el ámbito de la salud, por ejemplo, se utiliza para la predicción de enfermedades, ayudando a identificar factores de riesgo a partir de datos clínicos. Gracias a su capacidad para manejar datos faltantes y su robustez frente al ruido, permite a los investigadores obtener modelos predictivos confiables que pueden influir en la toma de decisiones médicas.
Otra aplicación notable de Random Forest se encuentra en la detección de fraudes financieros. Este modelo permite analizar patrones de comportamiento en transacciones y señalar actividades sospechosas en tiempo real. Al entrenar el modelo con un conjunto de datos diverso que incluye transacciones legítimas y fraudulentas, se logra una clasificación efectiva que minimiza las pérdidas económicas y mejora la seguridad en el sector financiero.
Asimismo, la clasificación de imágenes es otra área donde Random Forest ha demostrado su eficacia. En particular, se utiliza en aplicaciones de visión por computadora para reconocer y clasificar objetos en fotografías. Su capacidad para manejar grandes volúmenes de datos y su resistencia al sobreajuste lo hacen ideal para entrenar modelos que requieren alta precisión, como en el diagnóstico médico a partir de imágenes radiológicas.
Por último, en el ámbito del marketing, Random Forest se emplea para segmentar clientes y predecir comportamientos de compra. Al analizar diferentes características de los consumidores, las empresas pueden implementar estrategias de marketing más efectivas y personalizadas, lo que aumenta la satisfacción del cliente y mejora las tasas de conversión. Esta capacidad para extraer patrones y tendencias de grandes conjuntos de datos es fundamental en un entorno empresarial cada vez más competitivo.
Comparación entre Random Forest y otros algoritmos de aprendizaje automático
El modelo de Random Forest se diferencia de otros algoritmos de aprendizaje automático, como la regresión logística y las redes neuronales, en su enfoque basado en múltiples árboles de decisión. Mientras que la regresión logística es más adecuada para relaciones lineales y puede ser menos efectiva con datos complejos, Random Forest maneja la no linealidad y la interdependencia entre las variables de manera más eficiente. Por otro lado, las redes neuronales, aunque potentes, requieren más ajustes y pueden ser propensas al sobreajuste si no se gestionan adecuadamente.
Además, otra gran diferencia radica en la interpretación de los modelos. Random Forest ofrece una mayor interpretabilidad al calcular la importancia de las variables, lo que ayuda a los analistas a entender qué características influyen más en las predicciones. En contraste, las redes neuronales operan como "cajas negras", lo que dificulta la extracción de conclusiones claras sobre cómo se toman las decisiones. Esta característica de Random Forest lo convierte en una opción preferida en campos donde la transparencia es crucial, como la medicina y la finanza.
En términos de rendimiento, Random Forest tiende a ser más robusto frente a overfitting que algoritmos como k-vecinos más cercanos (k-NN), que puede verse afectado por la dimensionalidad y el ruido en los datos. A diferencia de k-NN, que requiere un almacenamiento considerable de datos de entrenamiento para hacer predicciones, Random Forest realiza un aprendizaje más generalizado, lo que le permite adaptarse mejor a nuevos datos. Esto lo hace particularmente adecuado para problemas de clasificación complejos y de gran escala.
Finalmente, en comparación con otros algoritmos de ensemble, como el Boosting, Random Forest ofrece una ventaja en términos de velocidad de entrenamiento y facilidad de uso. El proceso de entrenamiento de Random Forest es generalmente más rápido y menos exigente en recursos computacionales, mientras que los métodos de boosting pueden requerir configuraciones más complejas. Esto hace que Random Forest sea una opción preferida para quienes buscan un equilibrio entre rendimiento y eficiencia en sus proyectos de ciencia de datos.
Mejores prácticas para implementar Random Forest en proyectos de ciencia de datos
Para implementar de manera efectiva el modelo de Random Forest en proyectos de ciencia de datos, es crucial realizar una adecuada selección de características. Esto implica analizar y reducir la dimensionalidad de los datos, eliminando variables irrelevantes que puedan introducir ruido en el modelo. Un enfoque común es utilizar técnicas como la importancia de características para identificar cuáles aportan más valor a la predicción y, por ende, optimizar el rendimiento del modelo.
Otro aspecto importante es ajustar correctamente los hiperparámetros del modelo. Elementos como el número de árboles en el bosque y la profundidad máxima de cada árbol pueden influir significativamente en la capacidad del modelo para generalizar. Se recomienda realizar una búsqueda de hiperparámetros a través de métodos como la validación cruzada, lo que permite encontrar la combinación óptima que minimiza el error de predicción.
La gestión de datos faltantes es un factor clave en la implementación de Random Forest. Aunque este modelo tiene la capacidad de manejar datos incompletos, es recomendable aplicar técnicas de imputación para asegurar que la calidad del conjunto de datos no se vea comprometida. Esto no solo mejora la precisión del modelo, sino que también proporciona resultados más confiables en la interpretación de las predicciones.
Finalmente, es esencial evaluar el rendimiento del modelo de manera continua. Utilizar métricas adecuadas, como la precisión, la recall y el F1-score, permite medir la efectividad del modelo en conjunto y realizar ajustes necesarios en caso de que el rendimiento no sea el esperado. La evaluación continua garantiza que el modelo siga siendo relevante y útil a medida que se incorporan nuevos datos y se actualizan los patrones.
Iniciar Sesión HBO: Guía Paso a Paso

Cómo darse de baja de DAZN - Guía paso a paso
Plataformas Streaming: Comparativa y Precios 2024

Iniciar Sesión Netflix: App, PC o TV

Móviles con Tapa 2023: La Mejor Selección

Manuales de Móviles: Guía Completa
Deja una respuesta
Contenido relacionado