
Entendiendo el Software Kafka y Sus Aplicaciones en el Manejo de Datos en Tiempo Real
En la era digital actual, la capacidad de procesar y manejar grandes volúmenes de datos en tiempo real es crucial para las organizaciones que buscan mantenerse competitivas. Apache Kafka se ha consolidado como una de las herramientas más poderosas en este ámbito, permitiendo la transmisión y el procesamiento de datos de manera eficiente y escalable.
Este artículo se enfocará en Entendiendo el Software Kafka y Sus Aplicaciones en el Manejo de Datos en Tiempo Real, explorando sus características, ventajas y cómo se integra en arquitecturas modernas de datos. A través de ejemplos prácticos, se revelarán las múltiples formas en que Kafka puede optimizar la gestión de información en tiempo real, transformando la manera en que las empresas operan y toman decisiones.
Navega por nuestro contenido
- ¿Qué es Apache Kafka y cómo funciona en el procesamiento de datos en tiempo real?
- Ventajas de utilizar Kafka en arquitecturas de microservicios para el manejo de datos
- Aplicaciones prácticas de Kafka en la transmisión de datos en tiempo real
- Cómo implementar un sistema de mensajería con Kafka para mejorar la eficiencia operativa
- Comparación de Kafka con otras soluciones de mensajería en el manejo de datos
- Mejores prácticas para optimizar el rendimiento de Kafka en entornos de datos en tiempo real
¿Qué es Apache Kafka y cómo funciona en el procesamiento de datos en tiempo real?
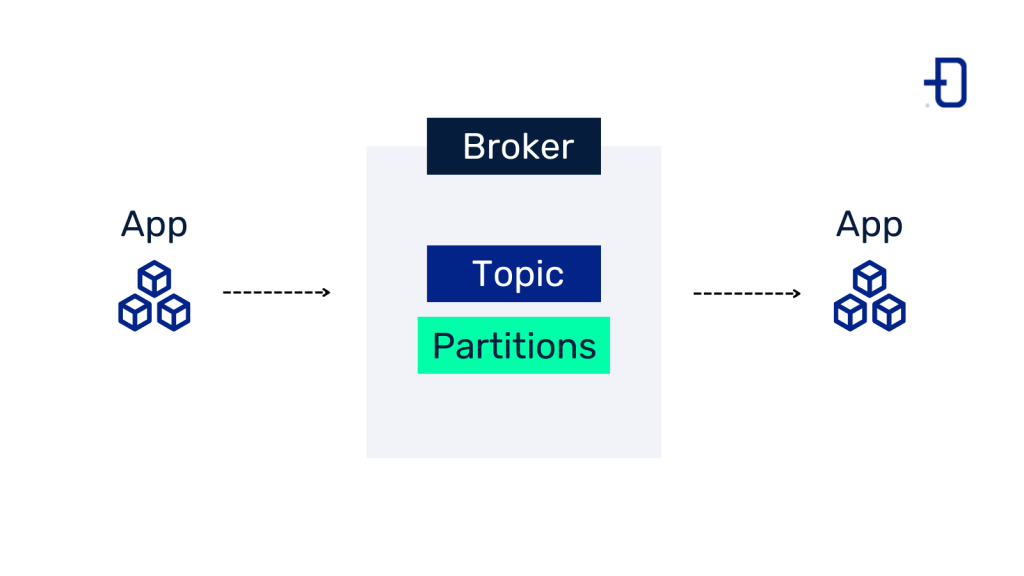
Apache Kafka es una plataforma de streaming de eventos que permite la recolección, el almacenamiento y el procesamiento de datos en tiempo real. Fue desarrollado originalmente por LinkedIn y luego donado a la Apache Software Foundation. Su arquitectura se basa en un modelo de publicación-suscripción, donde los productores envían mensajes a temas específicos y los consumidores se suscriben a esos temas para recibir los datos en tiempo real.
El funcionamiento de Kafka se centra en su estructura de clúster, que incluye varios componentes clave: brokers, productores, consumidores y temas. Cada componente desempeña un papel fundamental en el manejo eficiente de los datos. Los datos se distribuyen en particiones, lo que permite la escalabilidad horizontal y la tolerancia a fallos, asegurando que las aplicaciones puedan manejar cargas de trabajo variables sin comprometer el rendimiento.
Kafka se utiliza ampliamente en diversas aplicaciones, desde el monitoreo de sistemas hasta la integración de datos y el análisis en tiempo real. Algunas de sus aplicaciones más notables incluyen:
Otro articulo de ayuda: Todo lo que necesitas saber sobre SVC para potenciar tus habilidades técnicas
Todo lo que necesitas saber sobre SVC para potenciar tus habilidades técnicas- Streaming de datos en tiempo real.
- Procesamiento de eventos complejos.
- Ingesta de datos para análisis y machine learning.
- Integración entre microservicios.
En resumen, Apache Kafka se ha convertido en una herramienta esencial para las organizaciones que buscan implementar soluciones de procesamiento de datos en tiempo real. Su capacidad para manejar flujos de datos masivos y su arquitectura resiliente permiten a las empresas optimizar sus operaciones y mejorar la toma de decisiones basadas en datos actualizados al instante.
Ventajas de utilizar Kafka en arquitecturas de microservicios para el manejo de datos
Una de las principales ventajas de utilizar Kafka en arquitecturas de microservicios es su capacidad para manejar la comunicación asíncrona entre los distintos servicios. Esto permite que cada microservicio opere de manera independiente, lo que resulta en una mayor flexibilidad y escalabilidad. En un entorno donde los servicios pueden ser desplegados y actualizados de forma independiente, Kafka actúa como un intermediario que facilita el intercambio de mensajes sin que los servicios necesiten estar directamente conectados.
Además, Kafka proporciona alta disponibilidad y resiliencia mediante su diseño distribuido. Esto significa que si un nodo falla, el sistema puede seguir funcionando sin interrupciones, lo cual es crucial para mantener la continuidad del negocio. La replicación de datos en múltiples brokers asegura que la información no se pierda, lo que es fundamental en aplicaciones que requieren un manejo de datos en tiempo real.
Otra ventaja significativa es la capacidad de procesamiento en tiempo real de Kafka, lo que permite a las organizaciones tomar decisiones basadas en datos actuales. Gracias a su arquitectura de streaming, los datos pueden ser procesados y analizados al instante, facilitando respuestas rápidas a eventos relevantes. Esto es especialmente beneficioso en sectores como el financiero, donde cada segundo cuenta.
Finalmente, la integración con herramientas de análisis y procesamiento de datos es otra de las grandes ventajas de Kafka. Permite la conexión fácil con sistemas de análisis como Apache Spark o Apache Flink, lo que amplía las posibilidades de extraer valor de los datos que fluyen a través de los microservicios. Esta interoperabilidad posibilita crear soluciones más robustas y eficientes en el manejo de grandes volúmenes de datos.
Aplicaciones prácticas de Kafka en la transmisión de datos en tiempo real
Las aplicaciones prácticas de Apache Kafka en la transmisión de datos en tiempo real son numerosas y variadas, abarcando múltiples sectores y necesidades empresariales. Su capacidad para gestionar flujos de datos masivos lo convierte en una herramienta indispensable para la modernización de los procesos de negocio. Algunas aplicaciones destacadas incluyen:
- Monitoreo de sistemas: Permite la recopilación y análisis de métricas en tiempo real, facilitando la detección de anomalías.
- Transacciones financieras: Kafka puede gestionar el procesamiento de transacciones en tiempo real, asegurando la integridad y la velocidad necesarias en este ámbito.
- Notificaciones en tiempo real: Se utiliza para enviar alertas instantáneas a los usuarios sobre eventos relevantes.
- Ingesta de datos para plataformas de análisis: Mejora la eficiencia en la recopilación de datos para su posterior análisis.
Asimismo, Kafka es esencial en la arquitectura de microservicios, donde facilita la comunicación entre servicios de manera eficiente. Su modelo de publicación-suscripción permite que los servicios se comuniquen sin necesidad de estar acoplados, lo que fomenta una mayor agilidad en el desarrollo y la implementación. Entre sus aplicaciones en este contexto, podemos destacar:
- Integración de sistemas: Kafka actúa como un bus de eventos, conectando diferentes microservicios y asegurando la coherencia de los datos.
- Procesamiento de datos en tiempo real: Permite que los datos sean procesados a medida que llegan, ideal para análisis instantáneos.
- Escalabilidad de aplicaciones: La arquitectura distribuida de Kafka permite que las organizaciones escalen sus aplicaciones de manera sencilla y efectiva.
En ámbitos como el retail, Kafka se utiliza para mejorar la experiencia del cliente mediante la personalización basada en datos en tiempo real. Por ejemplo, se puede analizar el comportamiento de compra de los clientes en el momento y ofrecer recomendaciones instantáneas. Las características clave que lo hacen ideal para este tipo de aplicaciones incluyen:
- Latencia baja: Permite la transmisión rápida de datos entre sistemas.
- Alta disponibilidad: Asegura que la información esté siempre accesible, incluso en situaciones de fallo.
- Capacidad de procesamiento masivo: Maneja millones de eventos por segundo, ideal para grandes volúmenes de datos.
Finalmente, en el sector de la salud, Kafka se utiliza para la integración de datos clínicos, permitiendo el intercambio de información entre dispositivos médicos y sistemas hospitalarios en tiempo real. Esto facilita la toma de decisiones informadas y mejora la atención al paciente. Las aplicaciones en este ámbito son esenciales para:
- Monitoreo de pacientes: Recopila y transmite datos vitales en tiempo real.
- Análisis predictivo: Permite prever necesidades de atención médica basándose en datos históricos y actuales.
- Optimización de procesos: Mejora la eficiencia en la gestión de recursos hospitalarios.
Cómo implementar un sistema de mensajería con Kafka para mejorar la eficiencia operativa
Implementar un sistema de mensajería con Kafka puede ser un paso crucial para mejorar la eficiencia operativa de una organización. Para comenzar, es fundamental definir los temas que se utilizarán para clasificar los mensajes. Una vez establecidos, se debe configurar el clúster de Kafka, asegurando que los brokers estén correctamente distribuidos para maximizar la escalabilidad y la tolerancia a fallos. Esto permite que el sistema maneje un alto volumen de datos de manera eficiente y sin interrupciones.
Una vez que el clúster esté en funcionamiento, el siguiente paso es integrar los productores, que son las aplicaciones responsables de enviar los mensajes a los temas designados. Es recomendable implementar métricas de monitoreo para asegurar que los productores estén enviando datos de manera efectiva. Además, es importante que los consumidores se configuren adecuadamente para recibir y procesar esos mensajes en tiempo real, garantizando que la información fluya sin cuellos de botella.
La implementación también debe considerar el uso de particiones dentro de cada tema, lo que permite un procesamiento paralelo y optimiza el rendimiento del sistema. Esto es especialmente relevante en entornos donde el tiempo de respuesta es crítico. Además, la replicación de datos entre brokers es esencial para garantizar la disponibilidad y la resiliencia del sistema, permitiendo que la operación continúe incluso si uno de los nodos falla.
Finalmente, para maximizar el valor de un sistema de mensajería con Kafka, es recomendable integrar herramientas de análisis y procesamiento que permitan extraer insights valiosos de los datos en tiempo real. Esto no solo mejorará la toma de decisiones, sino que también puede habilitar nuevas oportunidades de negocio al permitir a las organizaciones reaccionar rápidamente a los cambios en el mercado y las preferencias de los clientes.
Comparación de Kafka con otras soluciones de mensajería en el manejo de datos
Cuando se compara Apache Kafka con otras soluciones de mensajería, se destacan varias diferencias clave. En primer lugar, Kafka es conocido por su capacidad de procesamiento en tiempo real y su alta capacidad de manejo de datos, lo cual lo convierte en una opción preferida para aplicaciones que requieren velocidad y eficiencia en la transmisión de información. A diferencia de sistemas como RabbitMQ o ActiveMQ, que se centran más en la mensajería tradicional, Kafka se orienta hacia el streaming de datos y la gestión de grandes volúmenes de eventos, permitiendo que las organizaciones manejen flujos masivos de información de manera efectiva.
Otra diferencia importante es la arquitectura de Kafka, que se basa en un modelo de publicación-suscripción y permite que los productores y consumidores operen de forma desacoplada. Esto contrasta con soluciones como JMS (Java Message Service), donde el acoplamiento puede ser más fuerte. En Kafka, los consumidores pueden leer datos a su propio ritmo, lo que permite una mayor flexibilidad y escalabilidad. Esta característica es vital para aplicaciones que necesitan adaptarse a cargas de trabajo cambiantes y demanda fluctuante.
Además, Kafka ofrece una sólida resiliencia y disponibilidad gracias a su diseño distribuido, lo que significa que puede manejar fallos de nodos sin perder datos. Esto es crucial en entornos donde la continuidad del negocio es fundamental. En comparación, sistemas como Redis Streams pueden no ofrecer el mismo nivel de persistencia de datos, ya que están más orientados a situaciones donde la latencia es crítica en lugar de la durabilidad de la información.
Por último, la integración de Kafka con otras herramientas de datos, como Apache Spark o Apache Flink, le otorgan una ventaja significativa para el análisis de datos en tiempo real. Esto no siempre es posible con otras soluciones de mensajería, que pueden no estar diseñadas para trabajar fácilmente con herramientas de procesamiento de datos. Esta interoperabilidad permite a las organizaciones construir arquitecturas de datos más robustas y eficientes, optimizando el flujo de información y mejorando la toma de decisiones basadas en datos.
Mejores prácticas para optimizar el rendimiento de Kafka en entornos de datos en tiempo real
Para optimizar el rendimiento de Kafka en entornos de datos en tiempo real, una de las mejores prácticas es ajustar la configuración de los brokers. Esto incluye la modificación de parámetros como la memoria asignada y el tamaño de la cola de mensajes. Un broker bien configurado puede manejar un mayor volumen de datos, lo que resulta en una transmisión más rápida y eficiente. Además, es vital asegurar que el hardware utilizado sea adecuado para la carga que se espera manejar.
Otra práctica recomendada es la implementación de particiones adecuadas dentro de los temas. Las particiones permiten un procesamiento paralelo, lo que mejora significativamente la capacidad de Kafka para manejar flujos masivos de datos. Es importante encontrar un equilibrio al determinar el número de particiones; demasiado pocas pueden causar cuellos de botella, mientras que demasiadas pueden complicar la gestión del clúster. Además, es esencial monitorizar la distribución de carga en las particiones para asegurarse de que estén balanceadas.
El uso de compresión de mensajes es otra estrategia eficaz para optimizar el rendimiento. Al activar la compresión, se reduce el tamaño de los datos que se envían a través de la red, lo que puede resultar en tiempos de respuesta más rápidos y menor uso de ancho de banda. Las opciones de compresión como gzip o snappy son populares y pueden ser seleccionadas según las necesidades específicas de cada aplicación.
Finalmente, es crucial implementar un sistema de monitoreo y alertas para vigilar el rendimiento de Kafka en tiempo real. Herramientas como Prometheus y Grafana pueden proporcionar métricas útiles sobre el estado del clúster, ayudando a identificar problemas antes de que afecten la operación. Un monitoreo adecuado garantiza que las organizaciones puedan reaccionar rápidamente a cualquier eventualidad que comprometa la eficiencia del sistema.
Iniciar Sesión HBO: Guía Paso a Paso

Cómo darse de baja de DAZN - Guía paso a paso
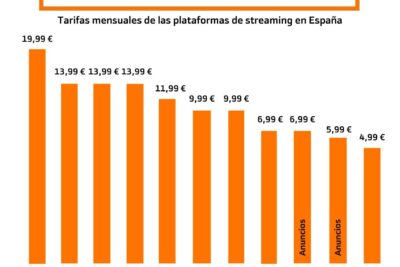
Plataformas Streaming: Comparativa y Precios 2024

Iniciar Sesión Netflix: App, PC o TV

Móviles con Tapa 2023: La Mejor Selección

Manuales de Móviles: Guía Completa
Deja una respuesta
Contenido relacionado