
Entendiendo la variable nominal en la investigación estadística y su importancia en el análisis de datos
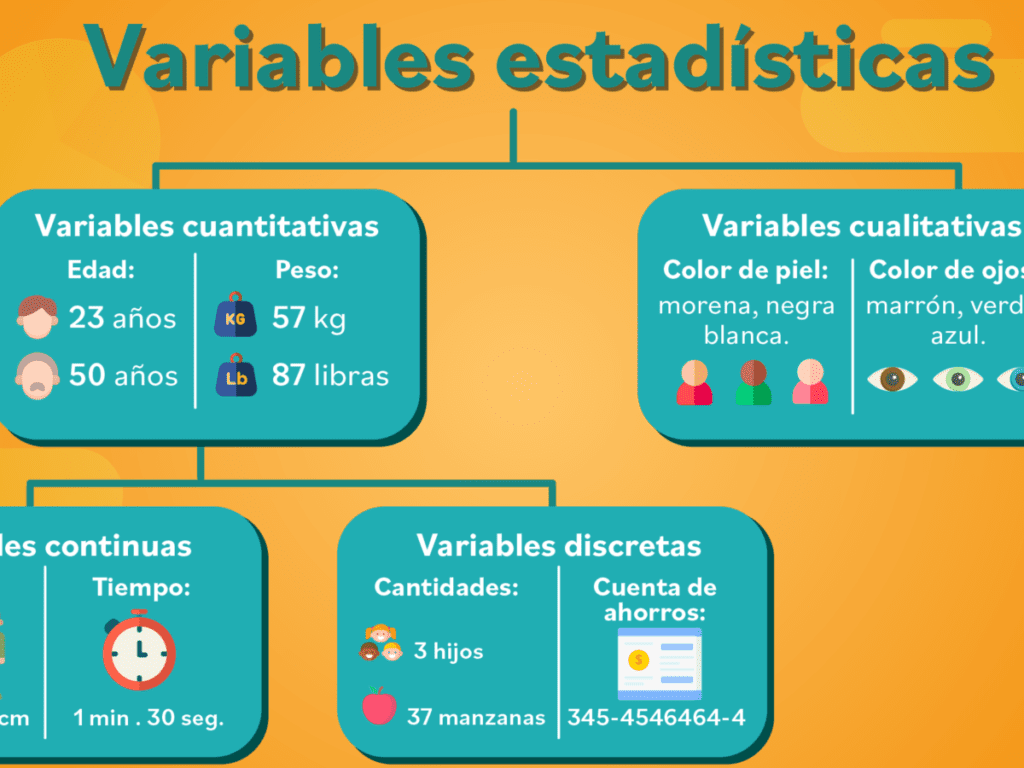
Las variables nominales son un componente fundamental en la investigación estadística, ya que permiten clasificar datos en categorías sin un orden jerárquico. Estas variables, como el género, la nacionalidad o el estado civil, son esenciales para entender la diversidad de un conjunto de datos y facilitar su análisis.
En este contexto, Entendiendo la variable nominal en la investigación estadística y su importancia en el análisis de datos se convierte en un tema crucial. La correcta identificación y manejo de las variables nominales no solo optimiza la recopilación de información, sino que también enriquece el proceso de interpretación de los resultados obtenidos en un estudio.
Navega por nuestro contenido
- ¿Qué es una variable nominal y por qué es crucial en la investigación estadística?
- Importancia de las variables nominales en el análisis de datos cualitativos
- Ejemplos de variables nominales en estudios estadísticos
- Diferencias entre variables nominales y ordinales en la investigación
- Cómo utilizar variables nominales en encuestas y cuestionarios
- Errores comunes al interpretar variables nominales en análisis de datos
¿Qué es una variable nominal y por qué es crucial en la investigación estadística?
Una variable nominal es un tipo de variable categórica que se utiliza para clasificar datos en grupos sin establecer un orden o jerarquía entre ellos. Estas variables son cruciales en la investigación estadística porque permiten al investigador segmentar la población en categorías distintas, lo que facilita el análisis de la diversidad y las tendencias en los datos recopilados. Ejemplos comunes de variables nominales incluyen colores, tipos de mascotas y preferencias de comida.
La importancia de las variables nominales en el análisis de datos radica en su capacidad para representar información cualitativa, lo que proporciona un contexto más rico para la interpretación de los resultados. A través de su uso, los investigadores pueden identificar patrones y relaciones en los datos que, de otro modo, podrían pasar desapercibidos. Además, el uso de variables nominales mejora la precisión y la validez de los estudios estadísticos.
Algunos aspectos clave sobre las variables nominales son:
Otro articulo de ayuda: Entendiendo los Modelos Lineales y su Aplicación en la Estadística
Entendiendo los Modelos Lineales y su Aplicación en la Estadística- No tienen un valor numérico asociado.
- Permiten la representación de categorías múltiples.
- Su análisis generalmente se realiza a través de frecuencias o porcentajes.
- Son fundamentales en encuestas y cuestionarios para clasificar respuestas.
En términos de análisis, las variables nominales pueden ser representadas en tablas de contingencia, donde las categorías se alinean para mostrar la frecuencia de cada grupo. Esto no solo simplifica la visualización de la información, sino que también ayuda a identificar tendencias y relaciones que son críticas para la toma de decisiones basadas en datos.
Importancia de las variables nominales en el análisis de datos cualitativos
Las variables nominales juegan un papel crucial en el análisis de datos cualitativos, ya que permiten categorizar información de manera efectiva. Este tipo de variables facilita la recopilación y clasificación de datos, lo que ayuda a los investigadores a comprender mejor las dinámicas de la población estudiada. Sin ellas, sería complicado identificar y analizar aspectos relevantes de un conjunto de datos, lo que podría llevar a conclusiones erróneas.
Una de las principales ventajas de las variables nominales es su capacidad para ofrecer una visión más completa de la diversidad en los datos. Al agrupar respuestas y características en categorías definidas, se pueden detectar patrones de comportamiento y preferencias que serían difíciles de observar en un análisis numérico. Esto es especialmente importante en estudios de mercado, donde entender las diferencias entre grupos puede guiar estrategias efectivas.
Además, el análisis de variables nominales es fundamental en la elaboración de informes y visualizaciones. Utilizando herramientas como tablas y gráficos de barras, los investigadores pueden presentar los resultados de manera clara y accesible. Entre los métodos de representación más comunes se encuentran:
- Tablas de frecuencia, que muestran el número de ocurrencias de cada categoría.
- Gráficos de pastel, que representan la proporción de cada grupo sobre el total.
- Gráficos de barras, que permiten comparar distintas categorías de manera visual.
Finalmente, la interpretación de los resultados obtenidos a partir de variables nominales no solo mejora la calidad del análisis, sino que también fortalece la base para la toma de decisiones informadas. Al considerar las características cualitativas de la población, los investigadores pueden ofrecer recomendaciones más acertadas y adaptadas a las necesidades específicas de su audiencia.
Ejemplos de variables nominales en estudios estadísticos
En el ámbito de la investigación estadística, las variables nominales son fundamentales para categorizar información cualitativa. Entre los ejemplos más comunes de estas variables se encuentran:
- Género (masculino, femenino, no binario)
- Nacionalidad (española, argentina, chilena)
- Estado civil (soltero, casado, divorciado)
- Tipo de mascota (perro, gato, pez)
Los estudios de opinión pública a menudo utilizan variables nominales para clasificar respuestas de encuestas. Por ejemplo, en una encuesta sobre preferencias de comida, las opciones pueden incluir:
- Vegetariana
- No vegetariana
- Vegana
- Pescetariana
Estas categorías no solo permiten a los investigadores segmentar la población, sino que también facilitan la identificación de tendencias en las preferencias alimenticias dentro de un grupo específico. Asimismo, el uso de variables nominales en estudios de mercado resulta vital, ya que permite analizar la satisfacción del cliente en función de diferentes características demográficas.
Adicionalmente, las variables nominales son esenciales en investigaciones sociales donde se categorizan aspectos como la religión. Por ejemplo, se pueden clasificar como:
- Cristianismo
- Islamismo
- Budismo
- Ateísmo
Estas categorías ofrecen una visión clara de la diversidad cultural y religiosa de una población, aportando datos valiosos para el análisis social y la formulación de políticas adecuadas a las necesidades de diferentes grupos.
Diferencias entre variables nominales y ordinales en la investigación
Las variables nominales y ordinales son dos tipos de variables categóricas fundamentales en la investigación estadística, pero difieren en su naturaleza y en la forma en que se utilizan. Mientras que las variables nominales representan categorías sin un orden específico, las variables ordinales, como el nivel de satisfacción o la clasificación de un producto, implican una jerarquía clara entre las categorías. Esto significa que, en las ordinales, se puede establecer que una categoría es superior o inferior a otra, lo que no es posible en las nominales.
Por ejemplo, en una encuesta sobre la satisfacción del cliente, las opciones podrían ser "muy insatisfecho", "insatisfecho", "satisfecho" y "muy satisfecho", lo que demuestra un orden. En contraste, las variables nominales en el mismo contexto podrían incluir categorías como "restaurante italiano", "restaurante chino" o "restaurante mexicano", donde no existe un ranking entre ellas. Esta diferencia es crucial en la investigación estadística, ya que determina los métodos de análisis y las conclusiones que se pueden extraer.
Algunas características que distinguen a las variables nominales de las ordinales son:
- Las variables nominales no tienen un orden intrínseco, mientras que las ordinales sí.
- Las nominales se utilizan para clasificar datos en grupos, mientras que las ordinales permiten comparaciones basadas en el rango.
- El análisis de variables nominales se centra en frecuencias y proporciones, mientras que el de las ordinales puede incluir medidas de tendencia central y dispersión.
En resumen, comprender la diferencia entre las variables nominales y ordinales es esencial para llevar a cabo un análisis estadístico riguroso. Al seleccionar el tipo adecuado de variable, los investigadores pueden obtener una representación más precisa de los datos y facilitar así la interpretación de los resultados en el contexto de la investigación. Esto contribuye a una mejor toma de decisiones y a la formulación de conclusiones válidas y relevantes.
Cómo utilizar variables nominales en encuestas y cuestionarios
Para utilizar variables nominales en encuestas y cuestionarios, es crucial definir claramente las categorías que se desean investigar. Al formular preguntas, los investigadores deben asegurarse de que las opciones de respuesta sean mutuamente excluyentes y exhaustivas, lo que significa que cada encuestado debe poder seleccionar una opción que se ajuste a su situación o preferencia. Por ejemplo, al preguntar sobre el tipo de transporte utilizado, las opciones pueden incluir "coche", "bicicleta", "transporte público" y "a pie".
Además, es importante presentar las opciones de forma clara y concisa. Utilizar una estructura sencilla en la pregunta y en las respuestas ayudará a los encuestados a comprender rápidamente lo que se les está pidiendo. Las listas desplegables o las casillas de verificación son herramientas efectivas para recolectar datos de variables nominales, ya que permiten múltiples selecciones y simplifican la respuesta. Esto es fundamental para asegurar que la recopilación de datos sea efectiva y precisa.
También se debe considerar la posibilidad de incluir una opción "otro" para capturar respuestas que no encajen en las categorías predefinidas. Esto es especialmente relevante en encuestas sobre características demográficas o preferencias, donde puede haber una amplia variedad de respuestas posibles que no se pueden anticipar. Por ejemplo, si se pregunta sobre nacionalidad, incluir "otro" permitiría a los encuestados especificar su país si no está listado.
Finalmente, al analizar los resultados de las encuestas, es esencial utilizar herramientas adecuadas para representar las variables nominales. Gráficos de barras y tablas de frecuencia son altamente recomendables, ya que muestran de manera efectiva la distribución de las respuestas en cada categoría. De esta forma, los investigadores pueden identificar fácilmente tendencias y patrones significativos en los datos recolectados, optimizando así el análisis y la interpretación de los resultados.
Errores comunes al interpretar variables nominales en análisis de datos
Al interpretar variables nominales en el análisis de datos, uno de los errores comunes es confundirlas con variables ordinales. Esto puede llevar a asumir que hay un orden entre las categorías donde no lo hay. Por ejemplo, al clasificar tipos de fruta como "manzana", "plátano" y "naranja", no hay un criterio que determine cuál es "mejor" o "peor", lo que es fundamental recordar para evitar análisis erróneos.
Otro error frecuente es aplicar técnicas estadísticas inapropiadas para datos nominales. A menudo, los investigadores utilizan medidas de tendencia central como la media, que no tienen sentido en este contexto. En su lugar, se deben emplear análisis de frecuencias o porcentajes, que son más adecuados para entender la distribución de los datos nominales.
También es común que los investigadores ignoren la exclusividad de las categorías al diseñar sus encuestas. Es esencial que las opciones de respuesta sean mutuamente excluyentes para evitar confusiones. Por ejemplo, al preguntar sobre el estado civil, si no se incluye la opción "divorciado", los encuestados podrían sentirse obligados a seleccionar una categoría que no les representa correctamente.
Finalmente, la falta de atención a la exhaustividad de las categorías puede resultar en datos incompletos. Es recomendable incluir una opción como "otro" para capturar respuestas no previstas. Ignorar este detalle puede llevar a una pérdida significativa de información valiosa sobre las preferencias o características de los encuestados.
Iniciar Sesión HBO: Guía Paso a Paso

Cómo darse de baja de DAZN - Guía paso a paso
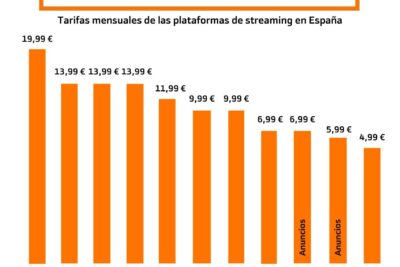
Plataformas Streaming: Comparativa y Precios 2024

Iniciar Sesión Netflix: App, PC o TV

Móviles con Tapa 2023: La Mejor Selección

Manuales de Móviles: Guía Completa
Deja una respuesta
Contenido relacionado