
Una Guía Completa sobre la Regresión Lineal y Múltiple para el Análisis de Datos

La regresión lineal y múltiple son herramientas fundamentales en el análisis de datos, permitiendo modelar relaciones entre variables y realizar predicciones precisas. Comprender su funcionamiento y aplicaciones es esencial para investigadores y profesionales que buscan extraer información valiosa de sus datos.
En este artículo, presentamos Una Guía Completa sobre la Regresión Lineal y Múltiple para el Análisis de Datos, donde exploraremos los conceptos básicos, las técnicas utilizadas y ejemplos prácticos. A través de esta guía, los lectores podrán adquirir el conocimiento necesario para aplicar estos métodos en sus propios proyectos de análisis de datos.
Navega por nuestro contenido
- Introducción a la regresión lineal: conceptos clave para el análisis de datos
- Diferencias entre regresión lineal simple y regresión múltiple en el análisis estadístico
- Cómo interpretar los resultados de un modelo de regresión lineal y múltiple
- Aplicaciones prácticas de la regresión lineal y múltiple en la ciencia de datos
- Errores comunes en la regresión lineal y consejos para evitarlos
- Mejores prácticas para construir un modelo de regresión eficaz en el análisis de datos
Introducción a la regresión lineal: conceptos clave para el análisis de datos
La regresión lineal es una técnica estadística que permite establecer una relación entre una variable dependiente y una o más variables independientes. Este método se utiliza ampliamente en el análisis de datos para realizar predicciones y comprender patrones subyacentes. Al aplicar la regresión lineal, es fundamental tener en cuenta ciertos conceptos clave que influirán en la calidad y la precisión de los resultados obtenidos.
Entre los conceptos más importantes en la regresión lineal, se encuentran:
- Variables dependientes e independientes: La variable dependiente es la que se desea predecir, mientras que las independientes son las que se utilizan para hacer esa predicción.
- Coeficientes: Representan el cambio en la variable dependiente por cada unidad de cambio en las variables independientes.
- Errores: La diferencia entre los valores observados y los valores predichos por el modelo, que se busca minimizar.
La elección del modelo adecuado es crucial para el éxito del análisis. Existen diferentes tipos de regresión lineal, como la regresión lineal simple, que involucra una sola variable independiente, y la regresión lineal múltiple, que considera múltiples variables. La comparación entre ambos métodos puede ser útil para determinar cuál se adapta mejor a los datos disponibles.
Otro articulo de ayuda: Todo lo que necesitas saber sobre el tamaño oficio y sus aplicaciones
Todo lo que necesitas saber sobre el tamaño oficio y sus aplicacionesEn términos de aplicación, es importante validar el modelo a través de métricas como el R-cuadrado, que indica el porcentaje de variabilidad de la variable dependiente que se explica por las variables independientes. Esta medida permite a los analistas evaluar la efectividad del modelo y realizar ajustes necesarios para mejorar su precisión.
Diferencias entre regresión lineal simple y regresión múltiple en el análisis estadístico
La regresión lineal simple se centra en la relación entre una única variable independiente y una variable dependiente. Esta técnica es ideal para situaciones en las que se busca entender cómo un solo factor afecta el resultado. En contraste, la regresión lineal múltiple permite incluir varias variables independientes, lo que proporciona un análisis más exhaustivo y la posibilidad de captar interacciones entre los distintos factores que influyen en la variable dependiente.
Otra diferencia clave radica en la complejidad del modelo. La regresión lineal simple es más fácil de interpretar, ya que se representa con una única línea recta en un gráfico bidimensional. Por su parte, la regresión múltiple implica un espacio multidimensional, lo que puede complicar la visualización y requiere de un análisis más detallado para entender el impacto de cada variable sobre el resultado final.
Las métricas de evaluación también difieren entre ambos enfoques. Mientras que en la regresión simple se puede utilizar el coeficiente de determinación R-cuadrado para medir la calidad del ajuste, en la regresión múltiple es fundamental observar el ajuste del modelo a través de ajustes como el R-cuadrado ajustado, que penaliza la inclusión de variables no significativas. Esto garantiza que solo se utilicen factores realmente relevantes en el análisis.
En resumen, elegir entre regresión lineal simple y múltiple depende de la naturaleza del problema y la cantidad de variables a considerar. Al analizar una situación compleja con múltiples factores, la regresión múltiple se convierte en una herramienta invaluable, permitiendo a los analistas obtener una comprensión más profunda de los datos y realizar predicciones más precisas.
Cómo interpretar los resultados de un modelo de regresión lineal y múltiple
La interpretación de los resultados de un modelo de regresión lineal y múltiple es clave para comprender las relaciones entre variables. En primer lugar, se deben analizar los coeficientes del modelo, que indican cómo afecta cada variable independiente a la variable dependiente. Un coeficiente positivo sugiere una relación directa, mientras que uno negativo implica una relación inversa. Por ejemplo, si el coeficiente de una variable es 2, esto significa que un incremento de una unidad en esa variable está asociado a un aumento de 2 unidades en la variable dependiente.
Además de los coeficientes, es fundamental considerar la significancia estadística de cada variable, que se evalúa a través de los valores p. Un valor p inferior a 0.05 generalmente indica que la variable tiene un efecto significativo en la variable dependiente. Esto se puede resumir en un listado:
- Coeficientes: Indican la magnitud y dirección del efecto.
- Valores p: Ayudan a determinar la significancia de cada variable independiente.
- R-cuadrado: Mide la proporción de variabilidad explicada por el modelo.
Otra métrica importante es el R-cuadrado ajustado, especialmente en regresión múltiple, ya que penaliza la inclusión de variables que no aportan significativamente al modelo. Esto evita el sobreajuste y permite una mejor interpretación de la calidad del modelo. A continuación se presenta una tabla comparativa:
| Métrica | Descripción |
|---|---|
| R-cuadrado | Mide la proporción de variabilidad explicada por el modelo. |
| R-cuadrado ajustado | Similar a R-cuadrado, pero ajustado por el número de variables independientes. |
| Valores p | Evalúan la significancia de cada coeficiente en el modelo. |
Finalmente, al interpretar un modelo de regresión, es crucial analizar también los residuos. Un análisis adecuado de los residuos puede revelar patrones que indican problemas en el modelo, como heterocedasticidad o falta de linealidad. Por lo tanto, una interpretación integral de los resultados no solo se centra en los coeficientes y sus significancias, sino que también considera la validación del modelo mediante el análisis de los residuos.
Aplicaciones prácticas de la regresión lineal y múltiple en la ciencia de datos
La regresión lineal y múltiple tiene diversas aplicaciones en la ciencia de datos, que abarcan múltiples sectores. En el ámbito de la **economía**, se utiliza para analizar el impacto de variables económicas sobre indicadores como el PIB o la inflación. Esto permite a los economistas realizar predicciones más precisas y tomar decisiones informadas basadas en datos históricos.
En el sector de la **salud**, la regresión múltiple se aplica para estudiar los efectos de diversos factores, como el estilo de vida, la genética y el ambiente, sobre la aparición de enfermedades. A través de este análisis, los investigadores pueden identificar las variables más significativas que contribuyen a la salud de la población y desarrollar estrategias para mejorarla.
Asimismo, en el ámbito del **marketing**, las empresas utilizan modelos de regresión para entender cómo diferentes factores, como los precios, la publicidad y la distribución, afectan las ventas de un producto. Este enfoque permite optimizar las estrategias de marketing y maximizar el retorno de la inversión. Algunos ejemplos de métricas que se pueden analizar incluyen:
- Impacto publicitario: Evaluar cómo la inversión en publicidad influye en las ventas.
- Segmentación de mercado: Identificar grupos de consumidores que responden de manera diferente a las campañas.
- Precios óptimos: Determinar el precio que maximiza las ganancias.
Finalmente, la industria tecnológica también se beneficia de la regresión lineal y múltiple al predecir el comportamiento del usuario en plataformas digitales. Al analizar datos de uso, las empresas pueden anticipar tendencias y mejorar sus productos o servicios, lo que resulta en una experiencia más personalizada para el usuario. En este sentido, la regresión se convierte en una herramienta clave para la innovación y el desarrollo continuo.
Errores comunes en la regresión lineal y consejos para evitarlos
Uno de los errores comunes en la regresión lineal es la suposición de que la relación entre las variables es lineal. Esto puede llevar a modelos inexactos si la verdadera relación es no lineal. Para evitar este problema, es importante realizar un análisis exploratorio de datos previo, que incluya la visualización de las relaciones entre las variables a través de gráficos de dispersión, lo que puede ayudar a identificar patrones no lineales y ajustar el modelo en consecuencia.
Otro error frecuente es no verificar la multicolinealidad entre las variables independientes. La multicolinealidad puede inflar las varianzas de los coeficientes y dificultar la identificación de la efectividad de cada variable. Para evitar este problema, puedes usar el VIF (Variance Inflation Factor) para evaluar la colinealidad; si el VIF de una variable es mayor a 10, considera eliminarla del modelo o combinarla con otras variables.
Además, es crucial prestar atención a la homocedasticidad de los residuos. Si los residuos presentan patrones o varían en función de las predicciones, esto indica que el modelo puede no estar ajustando adecuadamente los datos. Para prevenir este error, realiza pruebas de heterocedasticidad, como la prueba de Breusch-Pagan, y considera transformar las variables o aplicar métodos como la regresión robusta si es necesario.
Finalmente, no debes olvidar la validación del modelo. Al no separar un conjunto de datos de prueba, puedes caer en el sobreajuste, donde el modelo se adapta demasiado a los datos de entrenamiento y no generaliza bien. Utiliza técnicas como la validación cruzada para asegurar que tu modelo tiene un buen rendimiento en datos no vistos, lo que aumentará su fiabilidad y su capacidad predictiva.
Mejores prácticas para construir un modelo de regresión eficaz en el análisis de datos
Construir un modelo de regresión eficaz requiere atención a varios aspectos clave que aseguran resultados precisos y útiles. En primer lugar, es esencial realizar un análisis exploratorio de datos (EDA) antes de aplicar cualquier técnica de regresión. Esto incluye la visualización de relaciones entre variables, la identificación de outliers y la detección de distribuciones de las variables. Un EDA adecuado puede revelar patrones y facilitar la selección de las variables más relevantes para el modelo.
Otro aspecto importante es la selección de variables. Un modelo de regresión puede volverse complejo si se incluyen demasiadas variables independientes, lo que puede conducir a un sobreajuste. Se recomienda utilizar métodos como la regresión por pasos o la selección basada en criterios como AIC o BIC, que ayudan a identificar las variables que realmente contribuyen al modelo y mejoran su interpretabilidad.
Además, es fundamental garantizar la independencia de los residuos. Esto significa que los errores del modelo no deben estar correlacionados, ya que la presencia de autocorrelación puede distorsionar las estimaciones de los coeficientes. Para evaluar esto, puedes emplear pruebas estadísticas como la prueba de Durbin-Watson. Si encuentras que los residuos no son independientes, considera ajustar el modelo o incluir variables adicionales que expliquen esta correlación.
Finalmente, no subestimes la importancia de la validación del modelo. Es recomendable dividir los datos en conjuntos de entrenamiento y prueba para evaluar el rendimiento de tu modelo de regresión. Utilizar técnicas como la validación cruzada puede proporcionar una visión más clara de la capacidad de generalización del modelo, asegurando que sea robusto y capaz de hacer predicciones precisas en datos que no ha visto anteriormente.
Iniciar Sesión HBO: Guía Paso a Paso

Cómo darse de baja de DAZN - Guía paso a paso
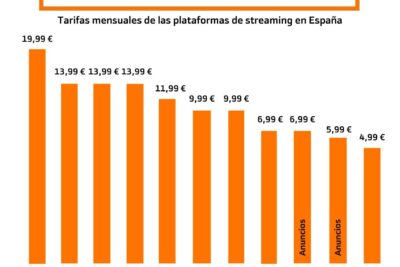
Plataformas Streaming: Comparativa y Precios 2024

Iniciar Sesión Netflix: App, PC o TV

Móviles con Tapa 2023: La Mejor Selección

Manuales de Móviles: Guía Completa
Deja una respuesta
Contenido relacionado