
Entendiendo los Modelos Lineales y su Aplicación en la Estadística
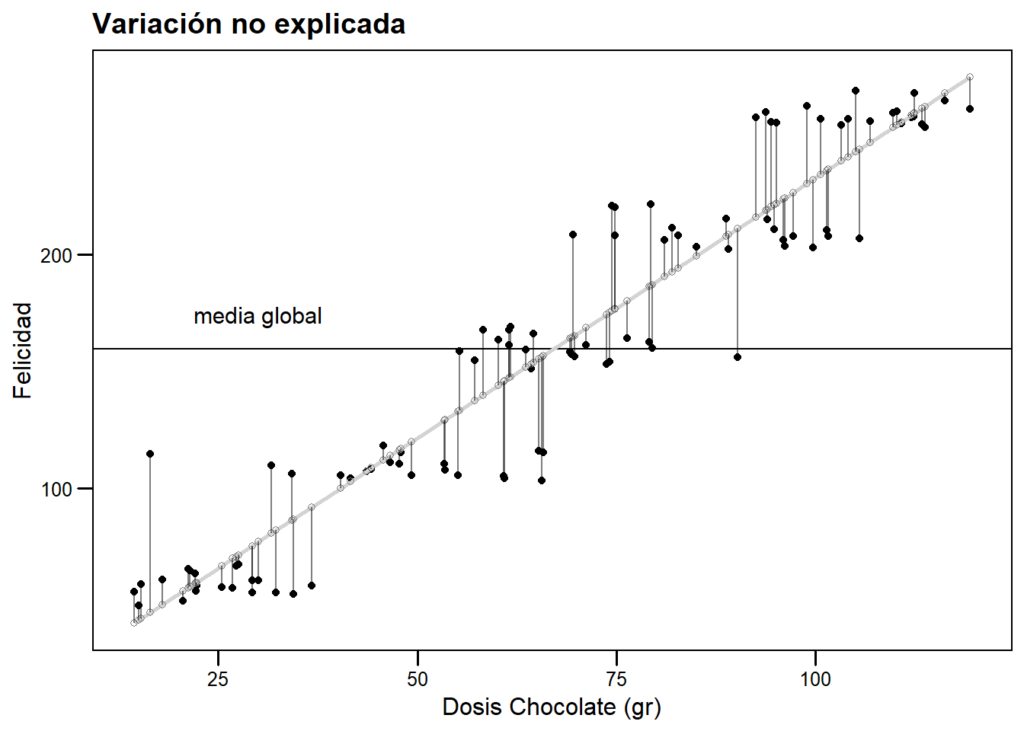
Los modelos lineales son herramientas fundamentales en el análisis estadístico, ya que permiten representar relaciones entre variables de manera sencilla y comprensible. Estas técnicas se utilizan en diversas disciplinas, desde la economía hasta la biología, facilitando la interpretación de datos y la predicción de comportamientos futuros.
En este artículo, nos enfocaremos en Entendiendo los Modelos Lineales y su Aplicación en la Estadística, explorando sus conceptos básicos, su construcción y las diferentes formas en que pueden ser utilizados para resolver problemas prácticos. A través de ejemplos concretos, esperamos ilustrar la relevancia de estos modelos en la toma de decisiones basada en datos.
Navega por nuestro contenido
- Introducción a los Modelos Lineales en Estadística: Conceptos Clave
- Tipos de Modelos Lineales: Diferencias y Aplicaciones
- Interpretación de los Resultados en Modelos Lineales: Guía Práctica
- Errores Comunes en la Aplicación de Modelos Lineales en Estadística
- Importancia de los Modelos Lineales en el Análisis de Datos
- Modelos Lineales vs. Modelos No Lineales: ¿Cuál Elegir?
Introducción a los Modelos Lineales en Estadística: Conceptos Clave
Los modelos lineales se fundamentan en la idea de que existe una relación lineal entre una variable dependiente y una o más variables independientes. Esta relación se expresa matemáticamente a través de una ecuación lineal, donde los coeficientes representan el impacto que tienen las variables independientes sobre la dependiente. Comprender estos conceptos es esencial para aplicar correctamente los modelos en el análisis de datos.
Entre los conceptos clave que se deben considerar al trabajar con modelos lineales, se encuentran:
- Variable dependiente: es la variable que se intenta predecir o explicar.
- Variables independientes: son las que se utilizan para explicar la variable dependiente.
- Coeficientes: representan el cambio esperado en la variable dependiente por cada unidad de cambio en la variable independiente.
- Residuales: son las diferencias entre los valores observados y los valores predichos por el modelo.
La validación de modelos es un aspecto crucial en el análisis estadístico, ya que permite evaluar la capacidad predictiva de un modelo lineal. Existen diversas técnicas para validar modelos, como la regresión cruzada y el análisis de residuos, que ayudan a identificar si el modelo se ajusta adecuadamente a los datos. Además, es fundamental verificar supuestos como la normalidad y homocedasticidad de los residuos para garantizar la fiabilidad de los resultados.
Otro articulo de ayuda: La Regresión No Lineal y su Importancia en el Análisis de Datos
La Regresión No Lineal y su Importancia en el Análisis de DatosFinalmente, es importante mencionar que los modelos lineales pueden extenderse a situaciones más complejas, como los modelos lineales generalizados, que permiten abordar casos donde las relaciones no son estrictamente lineales. Estos enfoques amplían las aplicaciones de los modelos lineales, haciendo posible su uso en una variedad de campos, desde la investigación médica hasta el análisis de mercado.
Tipos de Modelos Lineales: Diferencias y Aplicaciones
Los modelos lineales pueden clasificarse en diferentes tipos, cada uno con sus propias características y aplicaciones. Entre los más comunes se encuentran los modelos de regresión lineal simple y múltiple. La regresión simple se utiliza cuando se tiene una sola variable independiente, mientras que la regresión múltiple se emplea cuando hay varias variables independientes que influyen sobre la variable dependiente. Esta diferenciación es crucial para elegir la técnica adecuada según la complejidad del análisis requerido.
Otro tipo relevante son los modelos de efectos fijos y aleatorios, que se utilizan en el análisis de datos agrupados o en estudios longitudinales. Los modelos de efectos fijos permiten controlar variables no observadas que no cambian en el tiempo, mientras que los efectos aleatorios consideran que las diferencias entre grupos se deben a variaciones aleatorias. Esta distinción es fundamental para analizar correctamente los datos en estudios donde las observaciones están correlacionadas.
A continuación se presenta una tabla que resume las diferencias principales entre los tipos de modelos lineales:
| Tipo de Modelo | Descripción | Aplicaciones Comunes |
|---|---|---|
| Regresión Lineal Simple | Relación entre una variable dependiente y una independiente. | Predicción de ventas, análisis de precios. |
| Regresión Lineal Múltiple | Relación entre una variable dependiente y múltiples independientes. | Estudios de impacto, análisis de factores. |
| Efectos Fijos | Controla variables no observadas constantes en el tiempo. | Datos panel, estudios longitudinales. |
| Efectos Aleatorios | Considera variaciones aleatorias entre grupos. | Investigaciones con datos agrupados. |
Los modelos lineales generalizados son otra categoría importante, ya que extienden las aplicaciones de los modelos lineales a situaciones donde las variables dependientes no siguen una distribución normal. Estos modelos son útiles en campos como la biología y la economía, donde las variables pueden seguir distribuciones binomiales, de Poisson, entre otras. Comprender las diferencias y aplicaciones de estos modelos es esencial para realizar un análisis estadístico efectivo y preciso.
Interpretación de los Resultados en Modelos Lineales: Guía Práctica
La interpretación de los resultados en modelos lineales es una habilidad crucial para cualquier analista de datos. Al revisar los coeficientes, es vital entender cómo cada variable independiente afecta a la variable dependiente. Por ejemplo, un coeficiente positivo indica que a medida que la variable independiente aumenta, también lo hace la variable dependiente, mientras que un coeficiente negativo sugiere lo contrario. Esta relación debe contextualizarse dentro del marco del estudio para una interpretación precisa.
Otro aspecto importante en la interpretación de los resultados es el valor p asociado a cada coeficiente, que nos indica la significancia estadística de las variables independientes. Generalmente, un valor p menor a 0.05 se considera significativo. Es recomendable seguir estos pasos para evaluar la significancia:
- Revisar el valor p de cada coeficiente.
- Determinar si es menor que el nivel de significancia establecido (usualmente 0.05).
- Concluir si la variable tiene un impacto significativo en el modelo.
Asimismo, es fundamental analizar los residuos del modelo. Los residuos son las diferencias entre los valores observados y los valores predichos. Un patrón aleatorio en los residuos sugiere un buen ajuste del modelo. Para evaluar la adecuación del modelo, se pueden considerar las siguientes métricas:
- R²: Mide la proporción de la variabilidad de la variable dependiente que se explica por el modelo.
- RMSE (Error Cuadrático Medio): Indica la magnitud del error en las predicciones.
- Gráficos de residuos: Ayudan a visualizar si hay patrones anómalos.
Finalmente, la visualización de los resultados facilita la interpretación. Gráficos como los diagramas de dispersión y las líneas de regresión pueden ayudar a ilustrar la relación entre las variables. Presentar los resultados de esta manera no solo hace que los hallazgos sean más accesibles, sino que también permite a los interesados en el análisis comprender mejor las conclusiones alcanzadas.
Errores Comunes en la Aplicación de Modelos Lineales en Estadística
Uno de los errores comunes en la aplicación de modelos lineales es la multicolinealidad, que ocurre cuando las variables independientes están altamente correlacionadas entre sí. Esto puede distorsionar la estimación de los coeficientes y dificultar la interpretación de los resultados. Para detectar este problema, es recomendable calcular el Factor de Inflación de la Varianza (VIF), que ayuda a identificar qué variables podrían estar causando la colinealidad en el modelo.
Otro error frecuente es ignorar los supuestos del modelo. Los modelos lineales asumen, entre otras cosas, que los residuos son homocedásticos y que siguen una distribución normal. No cumplir con estos supuestos puede llevar a conclusiones incorrectas. Por lo tanto, es crucial realizar pruebas como el test de Breusch-Pagan para verificar la homocedasticidad y usar gráficos de probabilidad normal para examinar la normalidad de los residuos.
Además, muchos analistas cometen el error de sobrefit el modelo, añadiendo demasiadas variables independientes en un intento de mejorar la precisión. Esto puede llevar a un modelo que se ajusta muy bien a los datos de entrenamiento pero que tiene un rendimiento pobre en nuevos conjuntos de datos. Para evitar este problema, es recomendable utilizar técnicas de selección de modelos como regresión por pasos o criterios de información como el AIC o el BIC.
Finalmente, la falta de validación cruzada es un error que puede comprometer la robustez de los resultados obtenidos. La validación cruzada permite evaluar cómo se comporta el modelo en diferentes subconjuntos de datos, lo que es esencial para asegurar que las conclusiones son generalizables. Implementar k-fold cross-validation puede ayudar a prevenir el sobreajuste y proporcionar una medida más fiable del rendimiento del modelo.
Importancia de los Modelos Lineales en el Análisis de Datos
La importancia de los modelos lineales en el análisis de datos radica en su capacidad para simplificar la complejidad de las relaciones entre variables. Estos modelos permiten a los analistas identificar patrones y tendencias de manera efectiva, lo que facilita la comprensión de los datos recolectados. Al establecer relaciones lineales, los profesionales pueden predecir el comportamiento futuro de la variable dependiente en función de variaciones en las independientes, lo que resulta esencial en la toma de decisiones informadas.
Además, los modelos lineales son ampliamente utilizados debido a su facilidad de interpretación. Los coeficientes obtenidos de la regresión lineal indican claramente el impacto que tiene cada variable independiente sobre la variable dependiente. Esta claridad es fundamental en diversas aplicaciones, desde la investigación científica hasta el análisis de mercado, donde la comprensión precisa de los factores que influyen en un resultado es crucial para generar estrategias efectivas y basadas en evidencia.
Otro aspecto significativo es que los modelos lineales proporcionan una base sólida para la validación estadística. Al aplicar pruebas de significancia y evaluar el ajuste del modelo, los analistas pueden asegurar que las conclusiones extraídas son robustas y generalizables. Esto es vital en contextos de investigación donde la validez de los resultados puede influir en políticas, prácticas o desarrollos futuros en diferentes campos como la salud, la educación o la economía.
Finalmente, los modelos lineales son altamente versátiles y pueden adaptarse a diferentes conjuntos de datos y necesidades analíticas. A través de extensiones como los modelos lineales generalizados, se pueden abordar problemáticas más complejas que involucran diferentes distribuciones de datos. Esta adaptabilidad asegura que los modelos lineales permanezcan relevantes en un mundo donde el análisis de datos se vuelve cada vez más crucial en la toma de decisiones en múltiples disciplinas.
Modelos Lineales vs. Modelos No Lineales: ¿Cuál Elegir?
Cuando se trata de elegir entre modelos lineales y modelos no lineales, es fundamental considerar la naturaleza de los datos y el objetivo del análisis. Los modelos lineales son ideales para situaciones donde se presume que la relación entre variables es constante y predecible. Sin embargo, en escenarios donde las interacciones son más complejas y no se ajustan a una línea recta, los modelos no lineales pueden ofrecer un mejor rendimiento. Es esencial analizar las características del conjunto de datos antes de tomar una decisión.
Algunas ventajas de los modelos lineales incluyen:
- Facilidad de interpretación y comunicación de resultados.
- Menor riesgo de sobreajuste cuando se trabaja con conjuntos de datos pequeños.
- Menores requerimientos computacionales.
Por otro lado, los modelos no lineales pueden ser más apropiados en situaciones donde se espera que los cambios en la variable dependiente sean desproporcionados en relación con los cambios en las variables independientes. Estos modelos permiten capturar patrones más complejos, pero también requieren una mayor atención a la validación y la interpretación de resultados. Al considerar la complejidad del modelo, se debe estar dispuesto a invertir más tiempo en el ajuste y la evaluación.
A la hora de elegir entre ambos, es útil tener en cuenta:
- El tamaño del conjunto de datos: modelos lineales para datos pequeños y no lineales para datos grandes.
- La naturaleza de las relaciones: lineales vs. no lineales.
- Los recursos computacionales disponibles y la experiencia del analista.
Iniciar Sesión HBO: Guía Paso a Paso

Cómo darse de baja de DAZN - Guía paso a paso
Plataformas Streaming: Comparativa y Precios 2024

Iniciar Sesión Netflix: App, PC o TV

Móviles con Tapa 2023: La Mejor Selección

Manuales de Móviles: Guía Completa
Deja una respuesta
Contenido relacionado